
Today Reinforcement Learning (RL) has gathered much interests for building advanced LLMs.
The purpose of this post is to give you (both experienced LLM users and practitioners) fundamental insights for reinforcement learning (RL) adoption in LLM’s training.
Agenda
- LLM training before RL
- What is RL essentially ?
- RL in LLMs
- Where and How it’s used in today’s LLMs ?
I hope this post will give you the answer for questions – such as, “What is RL for ?” and “How RL matters in LLM’s training ?”.
LLM training before RL
LLM is essentially a token classifier, which outputs probabilities for all possible tokens.
Before InstructGPT (which is the previous version of the initial ChatGPT appeared in 2022), most of trainings in LLMs were “pretraining” and/or “supervised finetuning” (SFT).
These 2 training has different manners each other (one is self-supervised learning, and another is supervised), but both 2 methods are based on the regular classifier trainings in deep learning, in which target (label) exists and LLM predicts the target token (mostly, predicts the next token) during the training.
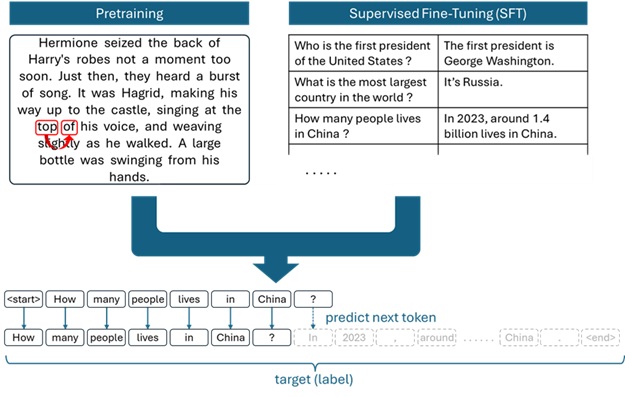
Note : See here for the primitive implementation of Transformer training.
In this training, LLM is trained to imitate the target – such like, Behavior Cloning (BC) method.
Even when the LLM’s output has the same meaning with different representations, the parameters in LLM are updated (changed) to exactly fit to the target (label) text.
“Children grow up by seeing and imitating adults.”
The training philosophy (training style) in pretraining and SFT is such like an elementary learning in human beings.
Note : Even though it’s just a training for behavior cloning (imitation), LLMs (deeply layered Transformers) can also learn the intention (context) behind the text, such like human beings do. However, tons of examples (training FLOPs) are required to learn intention through this style of training.
Here I don’t go so far, but please see emergent abilities (which is the obtained ability in this style of training) for details.
What is RL (Reinforcement Learning) essentially ?
Before jumping into RL adoption in LLMs, I will clarify the following points about RL fundamentals. :
- What kind of problems does RL solve ?
- How does RL solve these problems ?
The purpose of this post is not showing and explaining the detailed RL algorithms (such as, PPO).
Instead I’ll show you the following 4 primitive principles of RL in this post.
Note : If you want to deep dive, see here for the detailed implementation code and theoretical background about popular RL algorithms, including PPO.
1. RL is a training method based on “Reward”
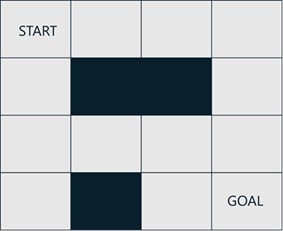
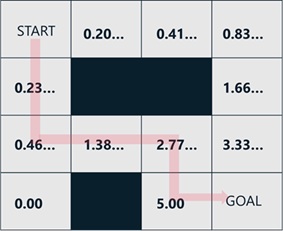
For simplification, now we consider the following simple maze.
In this maze game, an agent can take either of 4 actions – “go right”, “go left”, “go up”, or “go down”. The agent should then go to the goal state within 6 actions.
In Reinforcement Learning (RL), the reward should be given whenever the agent takes an action.
In this example, we give 10.0 as reward score when the agent reaches to the goal, and we give 0.0 otherwise.
For example, when the agent moves as follows (by the following 6 actions),
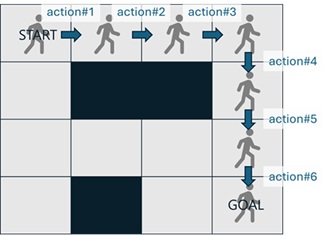
each given reward corresponding to each action will become as follows.
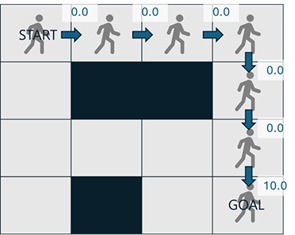
The function to give a reward to the agent is called a reward function – which might be implemented as a Python function, a neural network, or provided by a human or AI.
2. Expectation Maximization
Essentially RL optimizes to maximize the expectation.
Let’s see in our example.
To see how it trains, here I assume that an agent initially picks up one of the permitted directions with same probabilities.
For example, when the agent is in the following state, it can go to 3 directions with the same probabilities 1/3.
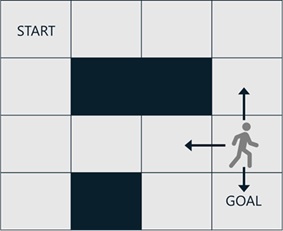
When this agent goes down, it can then get 10.0 as a reward (and it will then finish). But when it goes to other directions, it cannot get any rewards within 6 actions.
The expectation for the cumulative reward in this state will then become 3.333… , because

Let’s see the next state.
In the following state, the agent can go to 2 directions with the same probabilities 1/2.
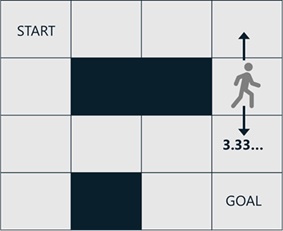
When it goes down, the expectation becomes 3.333…. But it goes up, it cannot get any rewards within 6 actions.
The expectation for cumulative reward in this state will then become 1.666… , because

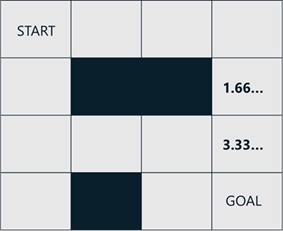
Same as above, you can get all expectations corresponding to every actions in every states as follows. (I note that, once an agent moves to left or up, the expectation becomes always 0.0. When an agent continues to move to right or down, the agent has an expectation in the following moving direction.)
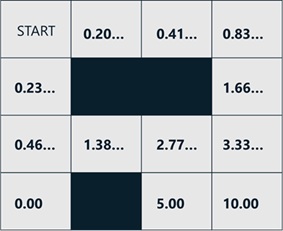
To get higher reward, the agent should take an action to the direction of higher expectation. (See below.)
The rest things to do is to update probabilities of taking actions to increase expectation, and repeat this process.
This shows an important aspect of RL training.
As you saw above, the agent is incentivized only on goal state (final state) and no incentives are given in others.
After the training, however, the agent finally learns the trajectory (the intermediate path) to get optimal and higher reward.
In reinforcement learning, the design of reward function is also very important for data scientists or developers.
In this expectation maximization, there is another thing you should know about.
In above example, we have calculated (computed) the exact expectation in each actions.
But, in most cases, the expectation cannot be computed exactly. For example, there will be infinite playing patterns in the chess game and we cannot then compute exact expectations also in chess games.
In real RL algorithms, the expectation is then estimated by a lot of trials (with current probabilities) during RL training.
3. Balance between Exploitation and Exploration
If the agent always picks up the action to the direction of higher expectation (i.e., “exploitation”), the agent won’t learn any more and the optimization then stops.
If the agent picks up random actions (i.e., “exploration”) on the other hand, the agent may find new optimal path, but it will be difficult to reach to the goal. This also causes serious degradation, because it will be hard to learn the latter stages and the agent may always fail in the early stages.
To speed up optimization, the agent should keep balance between exploitation and exploration, depending on the learning stages.
To address this concern, stochastic (not deterministic) approach is taken in policy-based RL algorithms.
In these RL algorithms, the output is not deterministic. In our maze case, for example, the output is not 4 discrete actions – “go right”, “go left”, “go up”, and “go down”.
Instead, it uses the stochastic (probabilistic) output – such like, “Going right is 10%, going left is 35%, going up is 30%, and going down is 25%”.
Then the next action is picked up with this probability.
Note : In most recent SOTA algorithms, the policy to pick up an action is stochastic.
Among RL algorithms, however, there also exist algorithms to use a deterministic policy, such like DDPG. (See here for details.)
By learning appropriate probabilities, it keeps balance between exploitation and exploration during training.
4. Bring your own Model (Policy)
You can build your own neural network to output probabilities for taking actions. This network is called policy or policy model.
In our maze example, this network should output probabilities of 4 distinct directions. (See below.)
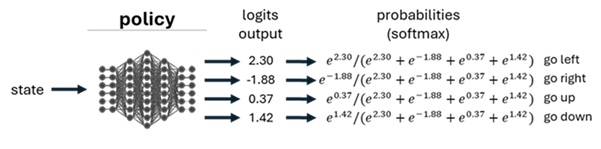
You can bring any kind of networks into the policy, depending on the task.
For example, in the case of car-driving agent which outputs steering direction seeing visual information, it might use some vision neural network (such as, ViT, U-Net, …) as a policy.
In policy-based algorithms, another neural network (except for policy model) is also used for optimization.
As I have mentioned above, the algorithm always estimates (predicts) the expectation corresponding to the given state. This estimation is realized by a neural network, called a value model.
RL algorithms based on policy (such as, PPO), therefore, trains 2 different neural networks simultaneously – policy model and value model.
Note : See actor-critic example for the primitive implementation (code example) of policy model and value model.
Depending on RL algorithms (such as, Twin-styled networks in RL), other types of neural networks are also used in RL algorithms.
RL in LLMs
Now let’s go back to LLMs.
As you know, LLM (autoregressive Transformer) is essentially a probabilistic model, which outputs token probabilities depending on the current context. (See here for the most primitive language model’s implementation and its concept without Transformer.)
Therefore, in policy-based RL, LLM (i.e, autoregressive Transformer) itself can be used as a policy model. (See below.)
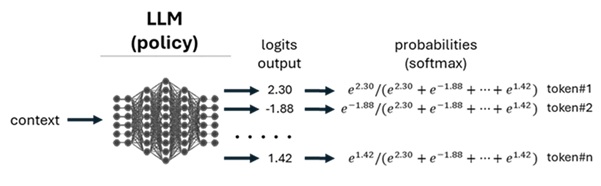
In LLM training, individual action (which is picked up using probabilities) is a selected token.
The state is the current token sequence (i.e., current context).
In RL algorithm, the state 


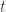
Any time the new action (i.e., new token) is taken by a policy (LLM), the current state (token sequence) will change.
In most cases, the active reward is set to the final output text (outcome state) as follows, not to individual tokens. (In above maze example, we also assigned a positive reward 10.0 only on the final state.)
Note : But there’re several exceptions. (There exists the case to assign positive/negative rewards in the middle of outputs.)
For example, see note for “process supervision” later.
As I have mentioned above, the trajectory of actions are learnt as a policy to maximize expectation (cumulative reward) in RL algorithm.
In LLM training, also, it finally learns a policy of token’s trajectory based on the given reward’s intention.
In this training philosophy, the agent directly learns a policy (intention) behind favorable behaviors by “carrot” (positive rewards) and “stick” (negative rewards) approach, unlike above imitation-style learning (pretraining / SFT).
Where and How it’s used in today’s LLMs ?
As you see, this style of training can be used in various situation in LLM training.
In this section, I focus on 2 main cases of today’s real adoption in LLM training – alignment and reasoning.
1. Alignment
RL in LLMs got a lot of attentions, because the initial release of OpenAI ChatGPT (exactly speaking, “InstructGPT”, the previous version of initial ChatGPT) has adopted RL in LLM training. (See the paper for details.)
By running pretraining and SFT (supervised finetuning), it can learn the exact answer, the exact sentence, or grammatical correctness.
For more favorable performance – such as, “nuance” (natural expression) or “readability”, they (OpenAI) tried to improve the expression of policy generated text by applying extra RL training. (See below for the whole training phases to build LLM.)

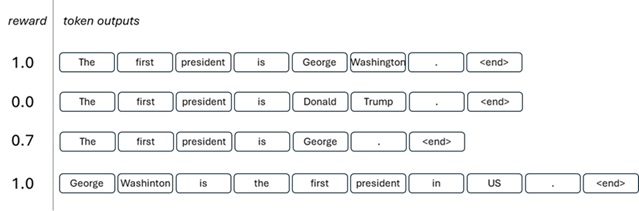
In this RL training (called “Reinforcement Learning from Human Feedback”, shortly RLHF), the following steps are taken to train LLM to generate human preferable outputs.
A prompt and several model outputs are sampled.
LLM is a probabilistic model, so its output may differ for the same instruction. (i.e., LLM generates multiple outputs for the same question.)
In first step in RLHF, collect multiple outputs for each questions.
For example, when the question “Who is the first president of the United States ?” is given, LLM may output the following 2 different answers.
- “It’s George Washington.”
- “George Washington is the first president in United States of America.”
A labeler ranks the outputs from best to worst.
A human labeler then generates labels for human preferability. To do this, a human labeler ranks its multiple outputs from best to worse.
For example, human labeler may like the output “George Washington is the first president in United States of America.” than another, one because it’s more polite and conscientious.
This data is used to train our reward model.
As I have mentioned above, the reward function is required to apply RL.
Now generate (train) a reward model (RM) using above human ranking results, which is a neural network model to output a reward score.
Often the language model itself is used for a reward model by changing the model’s output layer from token probabilities output to scalar value output, because the language model has much capability to capture language properties. (In this paper, GPT is also used for a reward model.)
Optimize a policy against the reward model using reinforcement learning.
Once the reward model (reward function) is obtained, you can now optimize LLM (i.e., policy) by applying RL.
The training (RLHF) is then completed.
You can also apply this method (RLHF) to finetune LLM in order to modify its behaviors to domain specific ones.
But remember that this method is used for more advanced refinement. And SFT (supervised finetuning) – i.e, cloning its behavior – will be a straightforward and fast method for gaining new behavior.
For example, even when you modify the tone of LLM as follows (modify outputs to frank and short style of answers), first it’s better to apply SFT by using below supervised examples. After SFT is completed, you can refine its behavior by applying RLHF (the method by RL) with model’s outputs.
| Who is the first president of the United States ? | Yep! It’s George Washington. |
| What is the most largest country in the world ? | Okay, that’s Russia! |
| How many people lives in China ? | Hmm, around 1.4 billion people lives in China in 2023. So huge! |
| …. | …. |
Table : example dataset for modifying tone of outputs
The following 3 training steps (SFT, generate RM, and RL) are then applied to get favorable behaviors, while the pretraining (self-supervised learning) is used to learn fundamental language properties.
From “Training language models to follow instructions with human feedback“
Note : For example, when the user asks to LLM with bad manners (such as, harmful, violent, or sexual), LLM may reject the responding for the asking. This model behavior for the safety is also gained in this alignment.
Today a lot of improved methods for alignment are researched, examined, and adopted in LLMs.
Among these methods, especially, DPO (Direct Preference Optimization) is a widely used method for alignment. DPO eliminates the complexity by skipping RM generation and directly learns nuance and readability using binary preferences.
Strictly speaking, DPO is not a method in reinforcement learning (RL), because this method doesn’t use a reward function.
Note : DPO is based on the equation of Bradley-Terry model, and this model is then based on binary preference. This method cannot handle structured preference, and several LLMs, hence, mixes other approaches (DPO and others) in alignment trainings.
2. Advanced Reasoning
Another adoption for applying RL in recent LLMs is for getting advanced reasoning abilities.
As you saw above, the purpose of above “alignment” in the training is for getting more natural expression (nuance) or readability – i.e., right-brained behaviors.
On contrary, “reasoning” is for a logical thinking – that is to say, left-brained ability.
Almost all LLMs (including general-purpose LLMs – such as, GPT, Llama, Mistral, Phi, …) have somehow logical thinking abilities – i.e., reasoning.
In general, autoregressive language models causally generates its outputs. In other words, each token is determined by seeing the preceding token sequence, from left to right.
With this style of outputs, when a difficult problem is given, a language model generates the primitive idea at first, then generates the next deeper idea by seeing the preceding token sequence, and repeats until it reaches to the answer, or until it finds that’s an unsolvable question. (See below.)
Example of Chain-Of-Thought (CoT) reasoning in general-purpose LLMs
But, in recent advancement, several LLMs – such as, OpenAI o-series, DeepSeek-R1, … – obtained extreme abilities to explore reasoning trajectory, and these models are called reasoning models, in contrast to the existing general-purpose models.
Reasoning model is tuned for solving difficult problems – such as, phD-level mathematical problems, competition-level code generation, or complex scientific open problems.
See here for early benchmark comparing with general-purpose models.
Ever since OpenAI has released the first version of reasoning model, o1, in Sep 2024, this advanced reasoning is gathering attention (such as, “how to build”, “how to improve”, …) in LLM research.
To come to the point, this ability is obtained with additional training by reinforcement learning (RL).
Note : Such like human beings do, firstly a reasoning model generates the output of thinking, called reasoning tokens – which consists of breaking-down, considering, and rethinking. After the final answer is found in reasoning trajectory, it then finally generates a cleaned answer, called completion tokens.
The advanced reasoning is realized not only by the training of reinforcement learning (RL), but this technique (“thinking before answering”) is also a big difference between general-purpose models and reasoning models.
In this post, however, the topic of “thinking before answering” is out of scope, because I want to focus on RL. If you’re interested in this technique, please see articles about test-time compute or inference-time scaling.
However, it’s hard to deal with determining rewards (whether it’s correct or wrong) for intermediate thinking logics in the training by RL.
In order to build reward functions, therefore, the rule-based verifications depending on the problems are often applied.
For example, if it has numeric or some kind of clear final answers (such as, numeric answers or LaTeX expression’s answers in mathematical problems), this final answer generated by the policy during training can be used for determining reward score.
In some problem domains, the instructions ask for not only final state, but also the intermediate states or the list of possible states (such as, “list all genes that may cause these symptoms in ranked order …”), and this result is then used to determine the reward score by rule-based function.
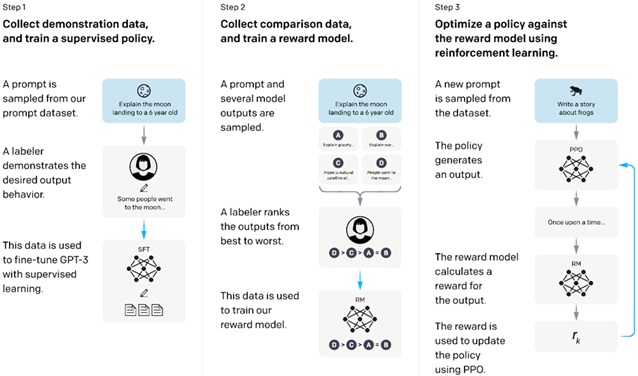
In code generation tasks, a code reward function may actually run (execute) the generated code in some emulator (such as, Piston execution environment) and check the result to determine the reward score. (See below.)

Note : Instead of “outcome supervision” which rewards to the final answer (waiting to reach to the end of token in a long, long reasoning), “process supervision” approach is sometimes used in RL, which is a rewarding for individual steps in reasoning trajectory. (You can also use existing PRM800K dataset to build Process-supervised Reward Model, PRM.)
Note : In DeepSeek-R1, accuracy rewards and format rewards are used for rule-based rewards. (DeepSeek-R1 is trained by outcome supervision.)
See the paper for details.
After these trainings, a LLM shows new levels of intelligence – such as, self‑verification or backtracking as follows (see the output “Wait”) in difficult problems, such like human beings do. (In the following output’s example, intermediate trajectory are eliminated, because it’s very long.)

Example of DeepSeek-R1’s output (Self‑verification / Backtracking)
Note : See “aha moment” phenomenon in DeepSeek-R1 paper for details.
As I have mentioned above, 2 neural networks – policy model and value model – are trained in today’s state-of-the-art policy based RL algorithm (such as, PPO). But DeepSeek AI (which company has built a famous reasoning model, DeepSeek-R1) has developed new light-weight RL algorithm, called GRPO (Group Relative Policy Optimization), which eliminates value models.
In policy-based algorithm, the estimation value for “how much expectation (cumulative reward) increases/decreases when policy parameters are updated” is called “Advantage”, which is written as “A” in the following picture.
The advantage is then represented by 
is the state (in this case, token sequence) in current timestep
.
is a taken action (in this case, a selected token) in current timestep
is a policy function (in this case, LLM). And
then returns all action’s probabilities (in this case, all token’s probabilities) in the state
.
is an obtained reward by taking an action
(i.e., depending on
is a value function. And then
is the expectation in current state.
is the expectation in the next state which is given by taking an action
Note : Throughout this post, I’m ignoring a discount rate not to make things complex.
See here for whole background in algorithms.
In the policy training, the policy
In today’s RL algorithm, the value model
In this way, today’s RL algorithm (such as, PPO) is resource intensive, because 2 different large models are trained simultaneously.
Note : Sometimes a part of parameters is shared between policy and value to reduce memory, but it will still have large overhead.
In GRPO, however, it samples (picks up) multiple outputs with current policy, and computes the following normalized value among this group in order to get an advantage.

where 
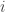



As you can see, the reward’s mean of samples obtained with current policy gives the estimation of value, and value model is no longer required in GRPO algorithm.
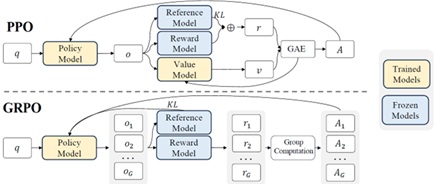
From: “DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models“
This technique reduces a footprint of memory (GPU memory) and makes it easy to train large reasoning models, such as DeepSeek-R1.
In this post, I have introduced the essential of RL and how RL technically contributes to LLM optimization.
RL is so powerful, but there are also some challenges to be solved. (For instance, one of such difficulties is “forgetting existing abilities”. Here I don’t go so far, but both above cases are well-designed to deal with.)
Reinforcement learning (RL) is so flexible, and this method will definitely be used for more various scenarios in LLM training in the future.
*This post is English version of this Japanese seminar (Apr 11, 2025).
Categories: Uncategorized

1 reply»