
In developing application with LLM, we often change (refine) the prompt text and should know how these changes affect the results. Even though some generated text is getting better, the other text might be degraded by the change of your prompt. (Some changes affect other results.)
This is why we need accountable metrics to measure the quality of LLM generated text in real application development.
In general, there exist 2 different approaches to measure the quality of generative outputs – code metrics and prompt metrics.
The code metrics is built by programming code.
The most common use-case for code metrics is rule-based statistical evaluation – such as, BLEU, ROUGE, etc. These metrics are based on mathematical statistics about tokens – such as, “how many of the tokens in the generated texts are perfectly aligned with the reference text tokens”, “how many n-grams in the generated text appear in the reference”, …
Note : There also exists a metric to measure a distance between generated text and reference text by using text embedding model (such like, GPT Similarity), or computes a similarity score for each token by using encoder-based language model (such like, BERT Score).
These approaches use language models, but don’t use prompts unlike prompt metrics.
On contrary, prompt metrics (or LLM-as-a-Judge method) can be obtained by asking to strong LLMs (such as, GPT-3.5, etc) for the quality of generated text.
Unlike statistical evaluation, you can easily construct and customize your own prompt metrics, however, it’ll have much overhead to call LLM especially when data is so large. Another caveat of prompt metrics is that the evaluation score may sometimes change, because the output of language model is not deterministic. (To make the evaluation stable, you may need to provide more clear criteria in evaluation prompt.)
Note : Luna is a low-cost foundation model which can be used for evaluating Generative AI applications (basically a foundation model for evaluation, i.e, a purpose-built foundation model).
In real cases, we often need scenario-specific metrics for LLM evaluation.
For instance, the false-negative degradation will be more serious rather than false-positive in disease detection application. In legal service, the generated text should exactly follow the description of multiple quoted text. In general RAG pattern, not only the quality of generated text, but the quality of extracted context should also be measured. Sometimes we have reference text (and measure a distance between reference text and generated text), but sometimes we don’t have. You might also need a local model for prompt metrics, because of enabling high throughput. You might customize evaluation for non-English prompts in prompt metrics …
These are why we often need our own metrics, though Azure (Azure AI Studio) provides some of built-in reusable metrics. Your own metric is also refined through development lifecycle, and should be involved into LLMOps – such as, tracking logs in history.
In this post, I’ll show you how to involve your own metrics (both code metrics and prompt metrics) with Azure AI SDK in step-by-step manner.
Note : Currently (May 2024), the custom metric is supported on AI SDK (code) or promptflow in Azure AI Studio. (To use custom metrics, it needs code integration.)
Here I don’t describe about promptflow, but see here for custom evaluator in promptflow SDK.
Install and Setup AI SDK
Azure provides AI CLI and SDK (currently, in Preview) to support a lot of works of generative AI throughout lifecycle – such as, provisioning, developing (building code), evaluating, deploying, and finally monitoring.
As you’ll see later, AI SDK will connect to Azure AI Studio, which is cloud-native and unified AI service in Microsoft Azure. Azure AI Studio is usually managed by GUI called Azure Portal, but you can also use Azure AI Studio from local environment, by code-first approach with AI CLI and SDK.
For preparation, here I install and setup AI SDK in my local environment.
Run the following command to install Python package of AI SDK (only evaluate sub-module) and as well as Azure CLI. (I assume that I’m working on local Ubuntu. The command for installing Azure CLI depends on your environment.)
# install AI SDKpip install azure-ai-generative[evaluate]pip install azure-identity# install Azure CLI (used when you connect to AI Studio)curl -sL https://aka.ms/InstallAzureCLIDeb | sudo bashNote : In this example, I have used the following version of Python packages.
azure-ai-generative==1.0.0b8azure-ai-resources==1.0.0b8azure-ai-ml==1.15.0
Custom Code Metric (Evaluation by Statistics)
Now let’s build and run example of custom metric.
Firstly, I’ll build a custom code metric.
Throughout examples in this post, we use the following data (only 3 lines of data) for measuring metric.
data.jsonl
{"question":"When and by Whom was United Stated found ?", "answer":"The United States was founded on July 4, 1776, when the Declaration of Independence was signed by the Founding Fathers of the United States."}{"question":"What is the most largest city in Japan and how big is it ?", "answer":"The most largest city in Japan is Tokyo, with a population of over 13.9 million people."}{"question":"Why does human being laugh ?", "answer":"It is believed that laughter is a form of social bonding that helps us connect with others. Laughter also releases endorphins, which are hormones that make us feel good."}For simplicity, here I build a trivial statistical metric to measure the length of generated text.
This example is so primitive, but you can also implement well-known statistical metric (such as, ROUGE metric, …) with available Python package or Hugging Face API. (See here for the list of available metrics in Hugging Face.)
Now I build a Python function to measure the length of each answer as follows.
async def answer_length(*, data, **kwargs): return len(data.get("answer")) # # when you return multiple results # return { # "answer_length": len(data.get("answer")), # "answer_length_div100": len(data.get("answer")) / 100 # }To measure with this custom metric, run evaluate() function in AI SDK.
from azure.ai.generative.evaluate import evaluateresult = evaluate( evaluation_name="eval-test01", data="./data.jsonl", task_type="qa", # supported task_type is ["qa", "chat"] metrics_list=[answer_length], output_path="./statistic_eval_output")Note : The
evaluate()function will log metrics/artifacts using MLflow. Here I don’t settracking_uriproperty and the error will then occur when it tries to write history with MLflow API.
Please ignore this error at this point. (Later I’ll integrate with Azure AI Studio project in cloud, by specifyingtracking_uriproperty.)
When you run the evaluation, the following output is written in ./statistic_eval_output/eval_results.jsonl.
As you can see below, the length of generated text (answer_length property) is written in the end of each line.
{"question":"When and by Whom was United Stated found ?","answer":"The United States was founded on July 4, 1776, when the Declaration of Independence was signed by the Founding Fathers of the United States.","answer_length":140}{"question":"What is the most largest city in Japan and how big is it ?","answer":"The most largest city in Japan is Tokyo, with a population of over 13.9 million people.","answer_length":87}{"question":"Why does human being laugh ?","answer":"It is believed that laughter is a form of social bonding that helps us connect with others. Laughter also releases endorphins, which are hormones that make us feel good.","answer_length":169}Note : In Sep 2024, new statistical quality evaluation metrics – such as, ROUGE, BLEU, METEOR, and GLEU – get available in public preview, accessible through the Azure AI Evaluation SDK (through
azure-ai-evaluationpackage).
See here for example in Python.
Custom Prompt Metric (Evaluation by LLM)
Prompt metric (or LLM-as-a-Judge method) measures the quality by asking to a language model (LLM). Here I’ll show you how to add your own prompt metric in AI SDK.
To build a custom prompt metric, you should create a jinja template to generate prompt for evaluation.
For example, the following template is to measure coherence of generated text. (In fact, this template is the same as built-in gpt_coherence metric in AI SDK.)
custom_template.jinja2
System:You are an AI assistant. You will be given the definition of an evaluation metric for assessing the quality of an answer in a question-answering task. Your job is to compute an accurate evaluation score using the provided evaluation metric.User:This Custom Coherence of an answer is measured by how well all the sentences fit together and sound naturally as a whole. Consider the overall quality of the answer when evaluating coherence. Given the question and answer, score the coherence of answer between one to five stars using the following rating scale:One star: the answer completely lacks coherenceTwo stars: the answer mostly lacks coherenceThree stars: the answer is partially coherentFour stars: the answer is mostly coherentFive stars: the answer has perfect coherencyThis rating value should always be an integer between 1 and 5. So the rating produced should be 1 or 2 or 3 or 4 or 5.question: What is your favorite indoor activity and why do you enjoy it?answer: I like pizza. The sun is shining.stars: 1question: Can you describe your favorite movie without giving away any spoilers?answer: It is a science fiction movie. There are dinosaurs. The actors eat cake. People must stop the villain.stars: 2question: What are some benefits of regular exercise?answer: Regular exercise improves your mood. A good workout also helps you sleep better. Trees are green.stars: 3question: How do you cope with stress in your daily life?answer: I usually go for a walk to clear my head. Listening to music helps me relax as well. Stress is a part of life, but we can manage it through some activities.stars: 4question: What can you tell me about climate change and its effects on the environment?answer: Climate change has far-reaching effects on the environment. Rising temperatures result in the melting of polar ice caps, contributing to sea-level rise. Additionally, more frequent and severe weather events, such as hurricanes and heatwaves, can cause disruption to ecosystems and human societies alike.stars: 5question: {{question}}answer: {{answer}}stars:Now, let’s measure the quality of generated text by using above template.
This also uses evaluate() function. Instead of passing plain Python function (see above code metric example), we pass a PromptMetric object in evaluate() function when it’s a prompt metric.
import osfrom dotenv import load_dotenvfrom azure.ai.resources.entities import AzureOpenAIModelConfigurationfrom azure.ai.generative.evaluate.metrics import PromptMetricfrom azure.ai.generative.evaluate import evaluatecustom_llm_metric = PromptMetric.from_template(path="custom_template.jinja2", name="custom_coherence")load_dotenv()deployment_name = os.environ["AZURE_OPENAI_DEPLOYMENT_NAME"]model_name = os.environ["AZURE_OPENAI_MODEL_NAME"]endpoint = os.environ["AZURE_OPENAI_ENDPOINT"]api_key = os.environ["AZURE_OPENAI_API_KEY"]aoai_configuration = AzureOpenAIModelConfiguration( api_version="2024-05-01-preview", api_base=endpoint, api_key=api_key, deployment_name=deployment_name, model_name=model_name, model_kwargs=None,)result = evaluate( evaluation_name="eval-test02", data="./data.jsonl", task_type="qa", # supported task_type is ["qa", "chat"] metrics_list=[custom_llm_metric], model_config=aoai_configuration, output_path="./llm_eval_output")Note : The
evaluate()function will log metrics/artifacts using MLflow. Here I don’t settracking_uriproperty and the error will then occur when it tries to write history with MLflow API.
Please ignore this error at this point. (Later I’ll integrate with Azure AI Studio project in cloud, by specifyingtracking_uriproperty.)Note : Currently the call by batch is not supported. At the bottom, the request to LLM is invoked one-by-one.
When you have run the evaluation, the following output is written in ./llm_eval_output/eval_results.jsonl.
As you can see below, the coherence metric (with rank 1 – 5) is written in the end of each line.
{"question":"When and by Whom was United Stated found ?","answer":"The United States was founded on July 4, 1776, when the Declaration of Independence was signed by the Founding Fathers of the United States.","custom_coherence":5}{"question":"What is the most largest city in Japan and how big is it ?","answer":"The most largest city in Japan is Tokyo, with a population of over 13.9 million people.","custom_coherence":4}{"question":"Why does human being laugh ?","answer":"It is believed that laughter is a form of social bonding that helps us connect with others. Laughter also releases endorphins, which are hormones that make us feel good.","custom_coherence":5}If the evaluation still isn’t good at certain aspects, add a criteria (or few-shots) in prompt template that directly shows how to evaluate these aspects correctly.
For instance, the paper “Who Validates the Validators? Aligning LLM-Assisted Evaluation of LLM Outputs with Human Preferences” proposes a solution to align LLM evaluators with human feedbacks (i.e, by collecting the results of feedbacks on generated outputs by humans).
The final template will then become an asset for your team and your company.
Note : There are a lot of works (researches) to improve evaluation’s accuracy in LLM-as-a-Judge – such as, G-Eval, Self-Rewarding Language Models, …
In this post, I have focused on custom metrics, but you can also use built-in metrics (the following list of metrics) for evaluation and safety.
Here I don’t describe about these built-in metrics, but see here for details. (Some of these built-in metrics also measure the quality of the extracted context, not only the generated answer.) :
gpt_groundednessgpt_relevancegpt_coherencegpt_fluencygpt_similaritygpt_retrieval_scoref1_scorehate_unfairnessviolenceself_harmsexual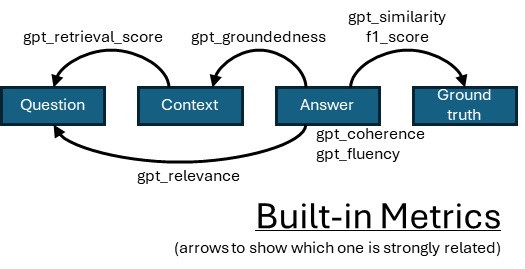
From : Evaluation Basics for Question and Answers using Large Language Models (Srikanth Bhakthan)
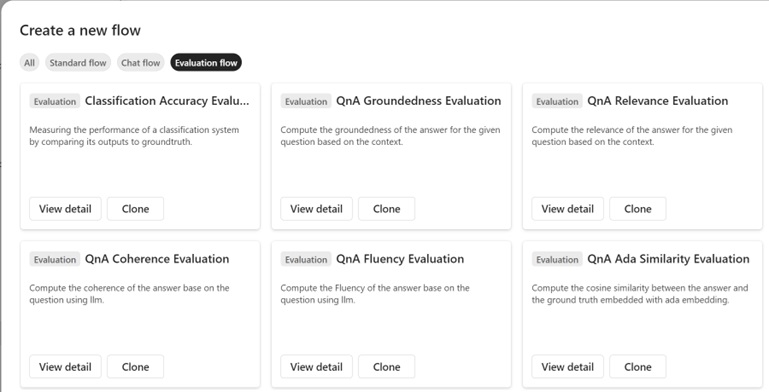
Note: You can also see the source code for these built-in metrics by cloning templates in promptflow. (See the following screenshot.)
Connect to Azure AI Studio project (LLMOps)
The evaluate() function in AI SDK will log metrics/artifacts using MLflow.
Azure AI Studio has dedicated MLflow tracking server in cloud, and you can then send run history into pre-configured project in AI Studio. (i.e, Azure AI Studio works as a centralized repository for logging in your team.)
In this section, finally we configure to collect run history into AI Studio, with AI SDK.
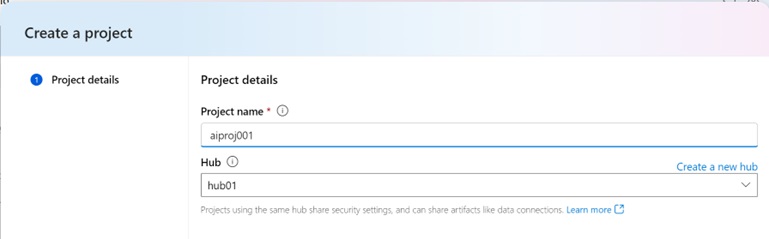
Firstly, let’s create a new project in Azure AI Studio.
You can see in the official document for details about how to create a new project.
In order to connect to a cloud project from local environment, you need to setup an appropriate credential.
In this example, I’ll use CLI credential. When you login to Azure with az command (Azure CLI command), the credential information is stored on ~/.azure directory. CLI credential then uses this information to connect to Azure.
Now, in the client console, let’s login to Azure with az command.
az loginNext, let’s run the following code. (Replace the following settings in AIClient() with your project’s settings.)
Almost is same as previous code, but here I have added tracking_uri property (in which, the AI Studio project is set with credential) in evaluate() function.
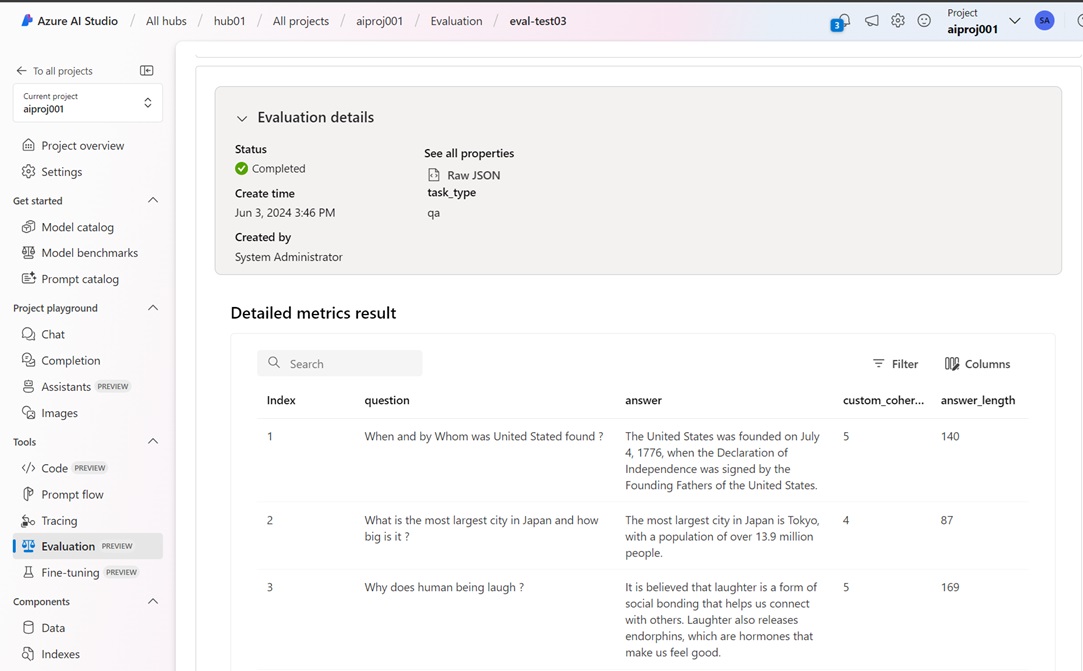
from azure.identity import AzureCliCredentialfrom azure.ai.resources.client import AIClientcredential = AzureCliCredential()ai_client = AIClient( subscription_id="xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx", resource_group_name="ai-studio-proj01", team_name="hub01", project_name="aiproj001", credential=credential,)tracking_uri = ai_client.tracking_uriresult = evaluate( evaluation_name="eval-test03", data="./data.jsonl", task_type="qa", # supported task_type is ["qa", "chat"] metrics_list=[custom_llm_metric, answer_length], model_config=aoai_configuration, output_path="./eval_output", tracking_uri=tracking_uri)After the evaluation has completed, go to above project in Azure AI Studio GUI (https://ai.azure.com/).
You can then see that the result is saved on evaluation history.
AI SDK is currently in preview (experimental), and I note that this might be changed in the future.
Stay tuned for updates.
Reference :
Azure AI Code Samples :
https://github.com/Azure-Samples/azureai-samples
Azure AI SDK for Python :
https://github.com/Azure/azure-sdk-for-python/tree/main/sdk/ai
Categories: Uncategorized

2 replies»