
(Please download source code from here.)
In this post’s series, I’m introducing multilingual fine-tuning in Hugging Face.
Especially, some languages, such like Japanese, Korean, and Chinese, don’t have an explicit whitespace tokenization, and we need to consider several things for language processing.
In this second post, I’ll show you multilingual (Japanese) example for text summarization (sequence-to-sequence task).
Hugging Face multilingual fine-tuning (series of posts)
- Named Entity Recognition (NER)
- Text Summarization
- Question Answering
Here I’ll focus on Japanese language, but you can perform fine-tuning in the same way, also in other languages.
mT5 (multilingual T5 model)
In text summarization, new text will be generated from input text by encoder-decoder architecture.
Unlike previous classification example, encoder-decoder transformers – such as, GPT-2, T5, or BART (not plain BERT) – are then preferred in these sequence-to-sequence (seq2seq) tasks.
In this example, we then fine-tune using mT5 model, which is the multilingual version of T5.
Note : If you’re new to language modeling in deep learning, see these tutorials for fundamental architectures (such as, language model, encoder-decoder, attentions, and transformers).
Originally T5 is based on a study of transfer learning in NLP and it then has ability to perform multiple tasks in a single model – such as, translation, linguistic acceptability (CoLA), semantic similarity (STSB), summarization, correction, etc.
For instance, when you want to summarize text with pre-trained T5 model, the format of input (source text) should be “summarize:<TEXT>”. For translation from English to German, it should be “translate English to German:<TEXT>”. (See below.)
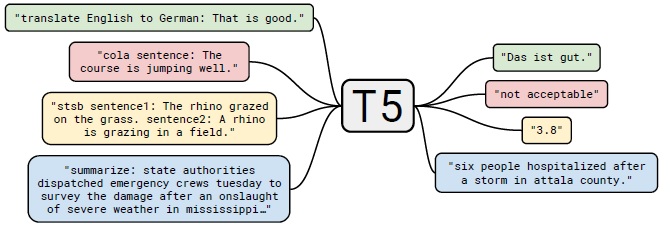
(FROM “Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer“)
The pre-trained T5 in Hugging Face is also trained on the mixture of unsupervised training (which is trained by reconstructing the masked sentence) and task-specific training.
Hence, using pre-trained T5, you can soon perform summarization without fine-tuning.
However, mT5 is pre-trained only by unsupervised manner with multiple languages, and it’s not trained for specific downstream tasks. To dare say, this pre-trained model has ability to build correct text in Japanese, but it doesn’t have any ability for specific tasks, such as, summarization, correction, machine translation, etc.
Therefore we should train (fine-tune) this model for downstream tasks, and here I’ll train using dataset for summarization in Japanese.
Note : You can also use other models (other encoder-decoder transformers) for multilingual summarization.
For popular languages (such as, English, French, German, etc), you can usefacebook/bart-large-cnnwhich is trained by using CNN/DailyMail dataset (in dataset, which has articles and summaries), and you can fine-tune with other (custom) dataset.
Pegasus model remarks high metrics for summarization, but we can’t use it because Pegasus in Hugging Face is not trained for multilingual corpus.
You can also use multilingual BLOOM model to generate sequence of tokens for a variety of languages, but I also didn’t use it, because currently BLOOM in Hugging Face isn’t trained in Japanese language.
For pre-trained Japanese model, you might also be able to use GPT-2 model provided by rinna Co., Ltd.Note : In this example, I will fine-tune for only summarization task, but you can also train for multiple tasks in a single mT5 model (by using inputs with prefix string).
Set up Environment
In this example, I have used GPU instance with Ubuntu Server 20.04 LTS image in Microsoft Azure.
Set up GPU drivers (NVIDIA CUDA) and install Hugging Face standard libraries (transformers, datasets, evaluate).
# compilers and development settingssudo apt-get updatesudo apt install -y gccsudo apt-get install -y make# install CUDA 11.4.4 (because I use old generation K80 GPU)wget https://developer.download.nvidia.com/compute/cuda/11.4.4/local_installers/cuda_11.4.4_470.82.01_linux.runsudo sh cuda_11.4.4_470.82.01_linux.runecho -e "export LD_LIBRARY_PATH=/usr/local/cuda-11.4/lib64" >> ~/.bashrcsource ~/.bashrc# install and upgrade pipsudo apt-get install -y python3-pipsudo -H pip3 install --upgrade pip# install pytorch with GPU accelerated# (see https://pytorch.org/get-started/locally/ )pip3 install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu114# install sentencepiece for multi-lingual modelingpip3 install omegaconf hydra-core fairseq sentencepiece# install huggingface librariespip3 install transformers datasets evaluate# install additional packagespip3 install protobuf==3.20.3pip3 install absl-py rouge_score nltkpip3 install numpy# install jupyter if you run code in notebookpip3 install jupyterProcess Data (Dataset)
Here I use XL-Sum Japanese dataset in Hugging Face, which is the annotated article-summary pairs in BBC news corpus.
This dataset has around 7000 samples for training in Japanese.
from datasets import load_datasetds = load_dataset("csebuetnlp/xlsum", name="japanese")ds
Note : XL-Sum (Cross-lingual Summarization) dataset has subsets for a lot of other languages, such as, Chinese, Korean, Arabic, and Indonesian. You will then be able to run the same fine-tuning program for other languages.
Unlike WikiLingua dataset, this dataset has abstractive summarization as follows. (On the other hand, WikuLingua has extractive summarization.)
ds["train"][0]
To generate inputs for fine-tuning, now we should tokenize text into ids.
First, we should prepare a tokenizer in pre-trained mT5 model.
from transformers import AutoTokenizert5_tokenizer = AutoTokenizer.from_pretrained("google/mt5-small")Now we convert text to token ids (the sequence of integer) as follows.
The generated inputs (tokenized_ds) will have token ids for article text and summary text, each of which is in input_ids and labels, respectively.
def tokenize_sample_data(data): # Max token size is 14536 and 215 for inputs and labels, respectively. # Here I restrict these token size. input_feature = t5_tokenizer(data["text"], truncation=True, max_length=1024) label = t5_tokenizer(data["summary"], truncation=True, max_length=128) return {"input_ids": input_feature["input_ids"],"attention_mask": input_feature["attention_mask"],"labels": label["input_ids"], }tokenized_ds = ds.map( tokenize_sample_data, remove_columns=["id", "url", "title", "summary", "text"], batched=True, batch_size=128)tokenized_ds
Note : It’s so challenging to operate long articles for most transformers, because the context size is usually limited to around 1000 tokens. Here I have also limited article text to 1024 tokens.
As we saw in my previous post, SentencePiece tokenizer (which is based on Unigram subword segmentation) is also used in this tokenization and we can then process multilingual languages which don’t have an explicit whitespace separator.
See my previous post for how it tokenizes source text. (Several pre-processing tasks, such as normalization, are also performed in the HuggingFace tokenizer.)
Note : SentencePiece tokenizer adds “
<s>” and “<\s>“, instead of “[CLS]” and “[SEP]“.
Load model and data collator
Before fine-tuning, load pre-trained model and data collator.
In HuggingFace, several sizes of mT5 models are available, and here I’ll use small one (google/mt5-small) to fit to memory in my machine.
The name is “small”, but it’s still so large (over 1 GB).
import torchfrom transformers import AutoConfig, AutoModelForSeq2SeqLMdevice = torch.device("cuda" if torch.cuda.is_available() else "cpu")# see https://huggingface.co/docs/transformers/main_classes/configurationmt5_config = AutoConfig.from_pretrained( "google/mt5-small", max_length=128, length_penalty=0.6, no_repeat_ngram_size=2, num_beams=15,)model = (AutoModelForSeq2SeqLM .from_pretrained("google/mt5-small", config=mt5_config) .to(device))Note : For the source code of this model, see
T5ForConditionalGenerationclass in GitHub repo.
Same as previous post, we also prepare data collator, which works for preprocessing data.
For the sequence-to-sequence (seq2seq) task, we need to not only stack the inputs for encoder, but also prepare for the decoder side. In seq2seq setup, a common technique called “teach forcing” will then be applied in decoder.
In Hugging Face, these tasks are not needed to be manually setup and the following DataCollatorForSeq2Seq will take care of all steps.
from transformers import DataCollatorForSeq2Seqdata_collator = DataCollatorForSeq2Seq( t5_tokenizer, model=model, return_tensors="pt")In this collator, the padded token will also be filled with label id -100.
This token will then be ignored in the sebsequent loss computation and evaluation.
Metrics for Text Generation
For instance, two sentences, “This is my book” and “The book is mine”, matches no tokens in each position, but it has similar meaning.
Measuring the quality of generated text is very difficult unlike classification tasks, such as, document classification, NER, or sentiment analysis.
BLEU and ROUGE are often used for measuring the quality of generated text.
Briefly speaking, BLEU measures how many of n-gram tokens in the generated (predicted) text are overlaped in the reference text. This score is used for evaluation, especially in the machine translation.
However, in summarization, we want all important words (which appears on the reference text) in the generated text. This is because we often use ROUGE metrics in summarization tasks.
The idea of ROUGE is similar to BLEU, but it also measures how many of n-gram tokens in the reference text appears in the generated (predicted) text. (This is why the name of ROUGE includes “RO”, which means “Recall-Oriented”.)
There also exist variations, ROUGE-L and ROUGE-Lsum, which also counts the longest common substrings (LCS) in ROUGE metrics computation.
With Hugging Face libraries, you can use built-in objects for scoring ROUGE metrics without needing to manually implement these logics. (See below.)
In this example, we should configure custom tokenization in metrics computation, because we need to process languages which don’t have an explicit space tokenization. (Otherwise, white space tokenization is used as default in ROUGE evaluation.)
Please change the following code for sentence break, when you use other languages except for Japanese. (Here I use Japanese punctuation “。” for sentence break.)
import evaluateimport numpy as npfrom nltk.tokenize import RegexpTokenizerrouge_metric = evaluate.load("rouge")# define function for custom tokenizationdef tokenize_sentence(arg): encoded_arg = t5_tokenizer(arg) return t5_tokenizer.convert_ids_to_tokens(encoded_arg.input_ids)# define function to get ROUGE scores with custom tokenizationdef metrics_func(eval_arg): preds, labels = eval_arg # Replace -100 labels = np.where(labels != -100, labels, t5_tokenizer.pad_token_id) # Convert id tokens to text text_preds = t5_tokenizer.batch_decode(preds, skip_special_tokens=True) text_labels = t5_tokenizer.batch_decode(labels, skip_special_tokens=True) # Insert a line break (\n) in each sentence for ROUGE scoring # (Note : Please change this code, when you perform on other languages except for Japanese) text_preds = [(p if p.endswith(("!", "!", "?", "?", "。")) else p + "。") for p in text_preds] text_labels = [(l if l.endswith(("!", "!", "?", "?", "。")) else l + "。") for l in text_labels] sent_tokenizer_jp = RegexpTokenizer(u'[^!!??。]*[!!??。]') text_preds = ["\n".join(np.char.strip(sent_tokenizer_jp.tokenize(p))) for p in text_preds] text_labels = ["\n".join(np.char.strip(sent_tokenizer_jp.tokenize(l))) for l in text_labels] # compute ROUGE score with custom tokenization return rouge_metric.compute(predictions=text_preds,references=text_labels,tokenizer=tokenize_sentence )Note : You can also specify multilingual stemmer for more confident scoring.
Note : As I have mentioned above, the padded token id becomes -100 by data collator and I then have also converted -100 into padded token id (0) before processing. (See above source code.)
Now let’s get ROUGE score for the plain mT5 model which is not trained for summarization.
As you can see below, the result is so bad, because it’s never trained for summarization.
from torch.utils.data import DataLoadersample_dataloader = DataLoader( tokenized_ds["test"].with_format("torch"), collate_fn=data_collator, batch_size=5)for batch in sample_dataloader: with torch.no_grad():preds = model.generate( batch["input_ids"].to(device), num_beams=15, num_return_sequences=1, no_repeat_ngram_size=1, remove_invalid_values=True, max_length=128,) labels = batch["labels"] breakmetrics_func([preds, labels])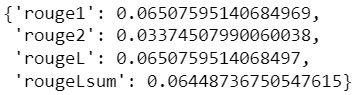
See below for details about BLEU and ROUGE metrics in HuggingFace.
Metric: bleu
https://huggingface.co/spaces/evaluate-metric/bleu
Metric: rouge
https://huggingface.co/spaces/evaluate-metric/rouge
Fine-Tuning for Summarization
Now let’s configure and run fine-tuning.
In this example, we use HuggingFace transformer trainer class, with which you can run training without manually writing training loop.
First we prepare HuggingFace training arguments.
To simplify sequence-to-sequence specific steps, here I use built-in Seq2SeqTrainingArguments and Seq2SeqTrainer classes, instead of usual TrainingArguments and Trainer.
In sequence-to-sequence model, the loss is computed by shifting labels (summary text) so that model can predict the next token depending on what has been output so far. (See here for example implementation.)
In regular evaluation, loss and accuracy are computed by comparing the generated logits with labels. As we saw above, however, we want to evaluate ROUGE score using the predicted tokens this time.
By setting predict_with_generate=True as follows in Seq2SeqTrainingArguments class, the predicted tokens are generated by model.generate() and it’s then passed into evaluation function.
from transformers import Seq2SeqTrainingArgumentstraining_args = Seq2SeqTrainingArguments( output_dir = "mt5-summarize-ja", log_level = "error", num_train_epochs = 10, learning_rate = 5e-4, lr_scheduler_type = "linear", warmup_steps = 90, optim = "adafactor", weight_decay = 0.01, per_device_train_batch_size = 2, per_device_eval_batch_size = 1, gradient_accumulation_steps = 16, evaluation_strategy = "steps", eval_steps = 100, predict_with_generate=True, generation_max_length = 128, save_steps = 500, logging_steps = 10, push_to_hub = False)Note : Do not use FP16 precision in mT5 fine-tuning.
Note : For stable convergence, here I have configured to linearly decrease learning rate by scheduler with
lr_scheduler_typesetting. Bywarmup_stepssetting, scheduling won’t work in the first 90 steps and will start from 91st step.
In this training arguments (above), there’s also another trick.
Because model (and data) is still so large, I then set the batch size to 2. You might think that this small batch size will prevent from stable convergence.
To avoid this problem, I have used gradient_accumulation_steps, which is a technique to aggregate the gradients from small batches.
Now let’s put it all together into trainer class and run fine-tuning as follows.
As I have mentioned above, you don’t need to manually write training loop. (Seq2SeqTrainer class will do all steps.)
from transformers import Seq2SeqTrainertrainer = Seq2SeqTrainer( model = model, args = training_args, data_collator = data_collator, compute_metrics = metrics_func, train_dataset = tokenized_ds["train"], eval_dataset = tokenized_ds["validation"].select(range(20)), tokenizer = t5_tokenizer,)trainer.train()Note : Because the cost of evaluation computation (ROUGE scoring) is so high in this example, I have then reduced the number of rows in validation set.
During training, you will find that ROUGE scores are increasing.
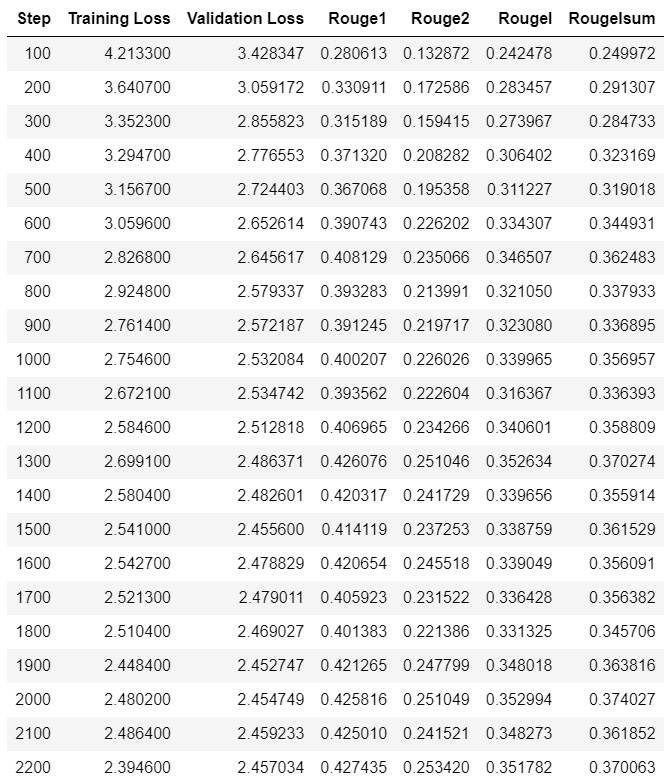
After the training has completed, you can save fine-tuned model with Hugging Face API as follows.
import osfrom transformers import AutoModelForSeq2SeqLM# save fine-tuned model in localos.makedirs("./trained_for_summarization_jp", exist_ok=True)if hasattr(trainer.model, "module"): trainer.model.module.save_pretrained("./trained_for_summarization_jp")else: trainer.model.save_pretrained("./trained_for_summarization_jp")# load local modelmodel = (AutoModelForSeq2SeqLM .from_pretrained("./trained_for_summarization_jp") .to(device))Generate Text (Summarize Japanese Text)
The following code generates text for summarization with fine-tuned model.
Here I generate the summarized text with test data, which has not seen in the training set.
from torch.utils.data import DataLoader# Predict with test data (first 5 rows)sample_dataloader = DataLoader( tokenized_ds["test"].with_format("torch"), collate_fn=data_collator, batch_size=5)for batch in sample_dataloader: with torch.no_grad():preds = model.generate( batch["input_ids"].to(device), num_beams=15, num_return_sequences=1, no_repeat_ngram_size=1, remove_invalid_values=True, max_length=128,) labels = batch["labels"] break# Replace -100 (see above)labels = np.where(labels != -100, labels, t5_tokenizer.pad_token_id)# Convert id tokens to texttext_preds = t5_tokenizer.batch_decode(preds, skip_special_tokens=True)text_labels = t5_tokenizer.batch_decode(labels, skip_special_tokens=True)# Show resultprint("***** Input's Text *****")print(ds["test"]["text"][2])print("***** Summary Text (True Value) *****")print(text_labels[2])print("***** Summary Text (Generated Text) *****")print(text_preds[2])
The model also learns a lot of contexts from training corpus, and the generated text isn’t just derived from input’s text (article), but it also has some bias by the learned contexts.
For instance, when the input’s article includes the word “virus” and not includes “coronavirus”, the model may possibly generate text with the word “coronavirus”, because a lot of COVID19’s text are included in the training set today.
I have published the fine-tuned model into Hugging Face hub, and you can soon try your own text in the inference widget. Let’s try a lot of text.
tsmatz/mt5_summarize_japanese (Hugging Face hub)
https://huggingface.co/tsmatz/mt5_summarize_japanese
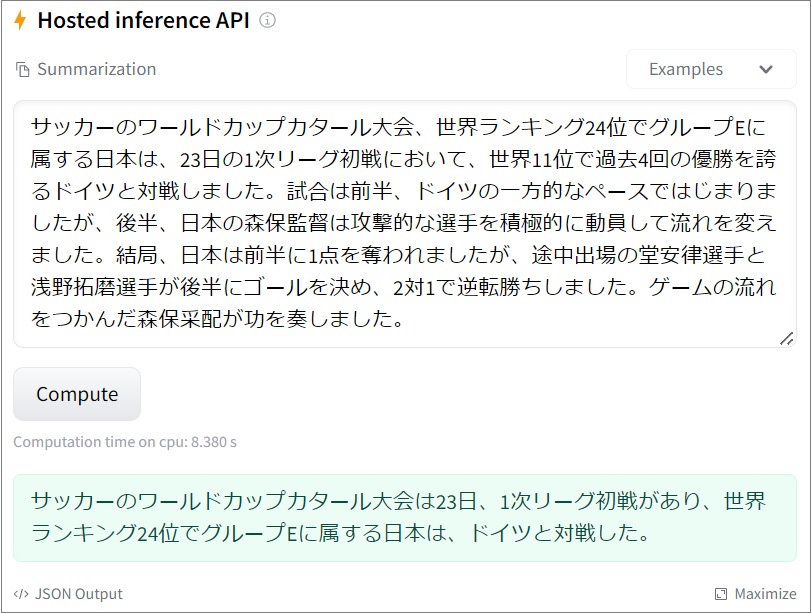
In this example, I have fine-tuned mT5 model with monolingual Japanese dataset.
As I have discussed in previous post, a model will perform a little better by multilingual (not monolingual) fine-tuning which performs training on multiple languages in a single model, because sister languages (the languages which has morphological similarity) can take advantage by transfer from each other.
For instance, let’s try fine-tuning with the mixture of Japanese and Korean language.
Reference :
Source code / Notebook (GitHub)
https://github.com/tsmatz/huggingface-finetune-japanese/
Fine-tuned Model (Hugging Face hub)
https://huggingface.co/tsmatz/mt5_summarize_japanese
Categories: Uncategorized

Thank you for uploading Japanese summarization model to HuggingFace. Other multilingual models didn’t work well on Japanese data.
LikeLiked by 1 person