
Microsoft Cognitive Services (powered by Microsoft Research) make you free from the difficulties of intelligence algorithms, and everyone who is not familiar with the data science can easily use this pre-built (ready-to-go) APIs for your application intelligence.
The natural language processing itself covers speech recognition, translation, sentiment analysis, summarization (which is also possible in Microsoft Word), language generation, etc… Microsoft Cognitive Services is having a lot of APIs (over 20) and corresponding APIs.
But we focus on the language understanding (the linguistic computation including tagging, parsing, etc) in this post, and focus on the only 2 APIs, which are Linguistic Analysis API and Language Understanding Intelligent Service (LUIS).
I hope this helps you understand the clear point of language understanding in Microsoft Cognitive Services.
Notice : This post doesn’t explain about “how to use”, and please refer the official document (Linguistic Analysis API, LUIS) for the api usage.
Linguistic Analysis API
If you need the fundamental language parsing capabilities, you must use this API. The Linguistic Analysis API returns the parsing result as json from the original sentences as following steps.
- Search available analyzers (calling rest api)
- Execute analysis (parsing) for the selected analyzer (calling rest api)
Today you can use the following 3 types of linguistic analyzers.
Token Analyzer (PennTreebank3 – regexes)
This is the most simple analyzer which just separates the sentences and tokenizes.
The following is the tokenized result of the sample sentence “I want a sweet-smelling flower with a red flowerbot.”
This result is not including so much useful information, but you can use this analyzer with other analyzers (you can specify multiple analyzers in one API call), and you can get the additional tokenization information with other analyzer’s result.
{ "analyzerId": "08ea174b-bfdb-4e64-987e-602f85da7f72", "result": [{ "Len": 52, "Offset": 0, "Tokens": [{ "Len": 1, "NormalizedToken": "I", "Offset": 0, "RawToken": "I"},{ "Len": 4, "NormalizedToken": "want", "Offset": 2, "RawToken": "want"},{ "Len": 1, "NormalizedToken": "a", "Offset": 7, "RawToken": "a"},{ "Len": 14, "NormalizedToken": "sweet-smelling", "Offset": 9, "RawToken": "sweet-smelling"},{ "Len": 6, "NormalizedToken": "flower", "Offset": 24, "RawToken": "flower"},{ "Len": 4, "NormalizedToken": "with", "Offset": 31, "RawToken": "with"},{ "Len": 1, "NormalizedToken": "a", "Offset": 36, "RawToken": "a"},{ "Len": 3, "NormalizedToken": "red", "Offset": 38, "RawToken": "red"},{ "Len": 9, "NormalizedToken": "flowerbot", "Offset": 42, "RawToken": "flowerbot"},{ "Len": 1, "NormalizedToken": ".", "Offset": 51, "RawToken": "."} ]} ]}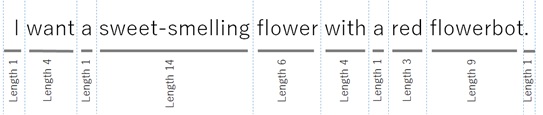
The sentence is not only separated by white space or punctuation marks, but is tokenized by the context in the sentence. For example, it can correctly tokenize like “what’s your name ?” (which is equivalent to “what is your name ?”), “Mr. Williams” (which doesn’t mean the punctuation mark), and …
Part-of-speech (POS) Tagging Analyzer (PennTreebank3 – cmm)
If you want to retrieve some keywords and analyze the sentence, the identification (noun, verb, etc) is often needed. For example, if you want the emotional keywords and measure the emotion, the adjective should be the key word.
This POS tagging analyzer identifies these tags.
The following is the result of this analyzer, using the input sentence “I want a sweet-smelling flower with a red flowerbot.”
{ "analyzerId": "4fa79af1-f22c-408d-98bb-b7d7aeef7f04", "result": [[ "PRP", "VBP", "DT", "JJ", "NN", "IN", "DT", "JJ", "NN", "."] ]}
| PRP | Personal pronoun |
| VBP | Verb |
| DT | Determiner |
| JJ | Adjective |
| NN | Noun, singular or mass |
| IN | Preposition or subordinating conjunction |
(See “Penn Treebank P.O.S. Tags – Penn (University of Pennsylvania)“)
The tag is not also distinguished only by words, but also the context is concerned.
For example, “dog” is usually the noun in the sentence, but it is used as “verb” in the following sentence. (I referred this example in “Wikipedia : Part-of-speech tagging“.) The tagging analyzer works well in this case. Trivial misspelling is also allowed in this tagging analysis.
“The sailor dogs the hatch.”
Constituency Forest Analyzer (PennTreebank3 – SplitMerge)
Assuming that you’re a shop owner of selling flowers in the internet and providing the intelligent search engine. Customers might input as follows.
“I want a red and sweet-smelling flower.”
“I want a sweet-smelling flower except for red flowers.”
“I want a sweet-smelling flower with a red flowerbot.”
You see that the each sentence is indicating the absolutely different items. But if you use POS tagging analyzer (previous one), you cannot distinguish the difference.
In such a case, you must use the constituency forest analyzer.
The following is the result of this analyzer in the case of the same sentence “I want a sweet-smelling flower with a red flowerbot.”
{ "analyzerId": "22a6b758-420f-4745-8a3c-46835a67c0d2", "result": ["(TOP (S (NP (PRP I)) (VP (VBP want) (NP (NP (DT a) (JJ sweet-smelling) (NN flower)) (PP (IN with) (NP (DT a) (JJ red) (NN flowerbot))))) (. .)))" ]}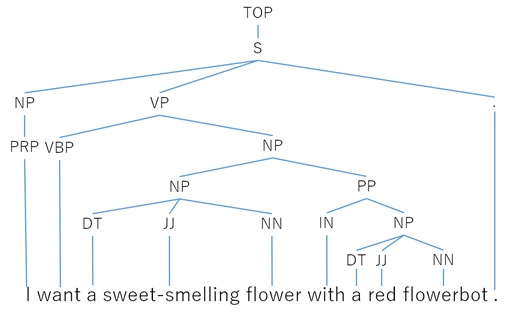
| S | simple declarative clause |
| NP | Noun Phrase |
| VP | Vereb Phrase |
| PRP | Personal pronoun |
| VBP | Verb |
| PP | Prepositional Phrase |
| DT | Determiner |
| JJ | Adjective |
| NN | Noun, singular or mass |
| IN | Preposition or subordinating conjunction |
(See “Penn Treebank II Tags – MIT“)
As you see, the result expresses the tree of structure. For example, it means that “a red flowerbot” is subordinating noun of “a sweet-smelling flower”.
Language Understanding Intelligent Service (LUIS)
The constituency forest analyzer (previous one) returns so much useful information, but it’s still difficult to understand this tree structure in your program code.
Language Understanding Intelligent Service (called “LUIS”) is not for just the parsing and analyzing like Linguistic Analysis API. But it provides the direct answer to some application’s scenarios for language understanding tasks, and your program code can soon proceed your application’s business logic.
For example, assuming that there’s an application for booking airline ticket. You might imagine that an application is having UI with the form and field of “departure location”, “destination location”, and “date/time”.
Using LUIS, you can retrieve these input values from natural language sentences (like, “I want a flight from Orlando to Seattle on 23rd Jul”). LUIS is very straightforward for language understanding tasks.
For example, you can directly retrieve the following values (departure location, destination location, date/time) enclosed by the branckets using LUIS.
Book a flight from {Orlando} to {Seattle} on {29/10/2016}.
Book me a flight to {Seattle} on {29th Oct}.
I want a flight from {Orlando} to {Seattle} {next Saturday}.
. . .
Notice : You see, the 2nd example lacks the input value “departure location”. But, in such a case, you can distinguish which parameters is needed (fullfilled) for action using LUIS, and you can ask the user to fill the required parameter.
When you use LUIS, first you register the scenarios (called “intent”) like “Book Flight”, “Get Weather”, etc… Next, for each intent, you register the sample sentences (called “utterances”) and teach the result. (When you push “train” button, LUIS learns the pattern.)
Now you can use LUIS calling rest endpoint. The rest returns the result as json, which matches the registered intent.
Notice : LUIS also provides the active learning which you can correct the sentences from unlabeled sentences.
LUIS is not only understanding words, but the context in sentence. For example, if you put “Book me a flight to etcetera etcetera on 29th Oct”, the word “etcetera etcetera” might be extracted as destination location.
Note that LUIS requires the registered intent beforehand. Therefore, it might not be used for the ad-hoc resolving, like natural language search, ad-hoc question answering (ad-hoc talking), etc…
Moreover, LUIS only retrieves the target key phase, and doesn’t analyze the phase itself. Let’s consider the next example.
“I want a flowerbot which matches the red flowers for my mother.”
LUIS might retrieve the phase “a flowerbot which matches the red flowers” as target, but it doesn’t mean “a flowerbot and red flowers.” If you want to analyze this phase meaning for acknowledging the exact customer needings, you must use the previous Linguistic Analysis API.
Notice : The name of Text Analytic API in Microsoft Cognitive Services reminds you the language parsing, but this API just analyzes the sentiment (human feeling of satisfied or not satisfied). Note that this doesn’t analyze the human emotion (glad, sad, angry, etc) like Emotion API (also, in Microsoft Cognitive Services), and the result is the scalar value (just the degree of sentiment). You can also retrieve the key phase which impacts to the sentiment. For example, if you collect the customer voice and you want to know what the customer is not satisfied with your services, you can also understand the possible reasons by retrieving this key phases (“facility”, “staff”, etc).
Categories: Uncategorized

Is it possible to use LUIS tech and build upon it to have it recognize another not yet Cortana supported language like a Slavic one?
LikeLike
LUIS is now supported in English, French, Spanish, Italian, and Chinese. You can check when you create the app in LUIS app portal (https://www.luis.ai/ApplicationList).
I think LUIS can be used with some kind of translation engine. For example, you can use the Skype translator, and change the language to English, and retrieve the answer using LUIS, and translate to your native language.
But, I think it’s not practical so much. (Because of the quality of translation mix.)
LikeLike
Is there a way Linguistic Analysis can be used to produce collocations (e.g. https://en.wikipedia.org/wiki/Collocation)?
LikeLike