
Important Note : Azure Data Lake Analytics will be retired on 29 February 2024. (See here.)
Azure Data Lake (ADL), which offers the unlimited data storage, is the reasonable choice (or cost effective) for the simple batch-based analysis.
You remember the data is more critical rather than the program ! In the case of analyzing data in your Azure Data Lake Store, you don’t need to move or download your data into the remote host. You can run the python or R code on Azure Data Lake Analytics in the cloud hosted.
Here I show you how to use this R extensions with some brief examples along with the real scenarios.
Note : In this post we consider the simple batch-based scenario. If you need more advanced scenarios with the data in ADL store, please use ADL store with Hadoop (HDInsight) with R Server, Spark, Storm, etc.
See “Benefits of Microsoft R and R Server” in my previous post for more details.
Note : U-SQL development with Python and R is also supported in Visual Studio Code. See “ADL Tools for Visual Studio Code (VSCode) supports Python & R Programming” in team blog. (Added on Nov 2017)
Setting-up
Before starting, you must prepare your Azure Data Lake Store (ADLS) and Azure Data Lake Analytics (ADLA) with Azure Portal. (Please see the Azure document.)
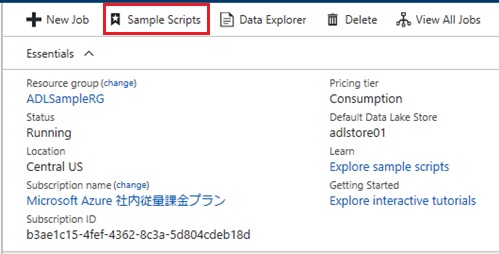
Next, on your Azure Data Lake Analytics blade, click [Sample Scripts], and select [Install U-SQL Extensions]. (See the following screenshot.)
It starts the installation of extensions in your Data Lake Analytics (ADLA).
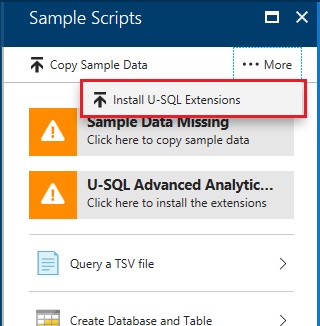
Let’s see what kind of installation was made.
After installation is completed, please click [Success] and [Duplicate Script] button. (The installation is executed as Data Lake job.)
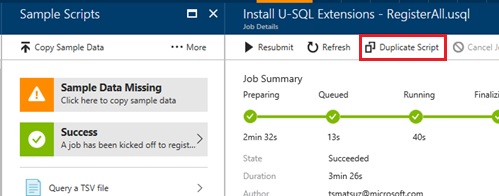
As you know, Data Lake Analytics is the .NET-based platform and you can extend using your own custom .NET classes.
R extension is the same. As you can see (see below) in this script job, the R extension classes (ExtR.dll) are installed in your Data Lake Analytics. (Note that the extensions of python and the extensions of cognitive services are also installed.)
As I show you later, you can use these installed classes in your U-SQL script.
Note : You can see these installed dll on /usqlext/assembly folder in your ADLS (Data Lake Store).
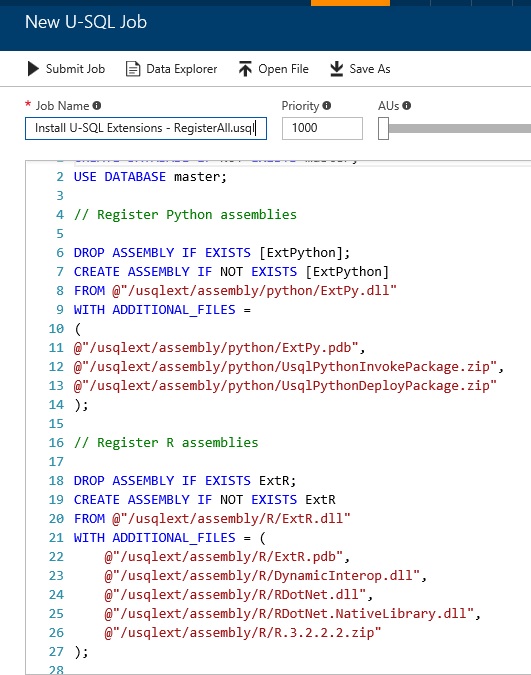
Let’s get started !
Now it’s ready.
You can find a lot of examples in /usqlext/samples/R on ADLS. (These are the famous iris classification examples.) You can soon run these U-SQL files (.usql files) with Azure Portal, Visual Studio, or Visual Studio Code (if using Mac), and see the result and how it works. (Here we use Visual Studio.)
For instance, the following is retrieving the data in iris.csv and analyzing for the prediction target “Species” with linear regression. (Sorry, but this sample is meaningless because it’s just returning the base64 encoded trained model. I show you some complete example later…)
R extension (ExtR.dll) includes the custom reducer (.NET class) named Extension.R.Reducer, then you can use this extension class with U-SQL REDUCE expression as follows.
REFERENCE ASSEMBLY [ExtR]; // Load libraryDECLARE @IrisData string = @"/usqlext/samples/R/iris.csv";DECLARE @OutputFilePredictions string = @"/my/R/Output/test.txt";DECLARE @myRScript = @"inputFromUSQL$Species <- as.factor(inputFromUSQL$Species)lm.fit <- lm(unclass(Species)~.-Par, data=inputFromUSQL)library(base64enc)outputToUSQL <- data.frame(Model=base64encode(serialize(lm.fit, NULL)),stringsAsFactors = FALSE)";@InputData = EXTRACT SepalLength double,SepalWidth double,PetalLength double,PetalWidth double,Species string FROM @IrisData USING Extractors.Csv();@ExtendedData = SELECT 0 AS Par, * FROM @InputData;@RScriptOutput = REDUCE @ExtendedData ON Par PRODUCE Par int, Model string READONLY Par USING new Extension.R.Reducer(command:@myRScript,rReturnType:"dataframe",stringsAsFactors:false);OUTPUT @RScriptOutput TO @OutputFilePredictions USING Outputters.Tsv();As you can see in this sample code, you can use inputFromUSQL for retrieving the input data in your R script. And you can use outputToUSQL as returned result to U-SQL. That is, your R script can communicate with U-SQL script by using these pre-defined variables.
Instead of using outputToUSQL, you can just write the result to the R output. For instance, you can rewrite the above example as follows. (I changed the source code with bold fonts.)
REFERENCE ASSEMBLY [ExtR]; // Load libraryDECLARE @IrisData string = @"/usqlext/samples/R/iris.csv";DECLARE @OutputFilePredictions string = @"/my/R/Output/test.txt";DECLARE @myRScript = @"inputFromUSQL$Species <- as.factor(inputFromUSQL$Species)lm.fit <- lm(unclass(Species)~.-Par, data=inputFromUSQL)library(base64enc)#outputToUSQL <-# data.frame(#Model=base64encode(serialize(lm.fit, NULL)),#stringsAsFactors = FALSE)data.frame( Model=base64encode(serialize(lm.fit, NULL)), stringsAsFactors = FALSE)";@InputData = EXTRACT SepalLength double,SepalWidth double,PetalLength double,PetalWidth double,Species string FROM @IrisData USING Extractors.Csv();@ExtendedData = SELECT 0 AS Par, * FROM @InputData;@RScriptOutput = REDUCE @ExtendedData ON Par PRODUCE Par int, Model string READONLY Par USING new Extension.R.Reducer(command:@myRScript,rReturnType:"dataframe",stringsAsFactors:false);OUTPUT @RScriptOutput TO @OutputFilePredictions USING Outputters.Tsv();We used inline R script in the above example, but you can also separate the R script from your U-SQL script as follows. (See the line with bold fonts.)
REFERENCE ASSEMBLY [ExtR]; // Load libraryDEPLOY RESOURCE @"/usqlext/samples/R/testscript01.R";DECLARE @IrisData string = @"/usqlext/samples/R/iris.csv";DECLARE @OutputFilePredictions string = @"/my/R/Output/test.txt";@InputData = EXTRACT SepalLength double,SepalWidth double,PetalLength double,PetalWidth double,Species string FROM @IrisData USING Extractors.Csv();@ExtendedData = SELECT 0 AS Par, * FROM @InputData;@RScriptOutput = REDUCE @ExtendedData ON Par PRODUCE Par int, Model string READONLY Par USING new Extension.R.Reducer(scriptFile:"testscript01.R",rReturnType:"dataframe",stringsAsFactors:false);OUTPUT @RScriptOutput TO @OutputFilePredictions USING Outputters.Tsv();Partitioning
By using REDUCE expression, you can separate your analysis workload by partitions. Each partitions can be executed in parallel, then you can efficiently predict some massive amount of data by using this partitioning capability.
To make things simple, let’s consider the following sample data. Here we use the first column as partition key.
test01.csv
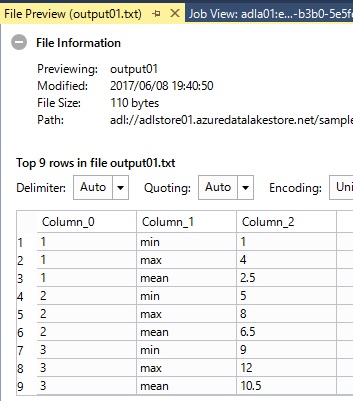
1,11,21,31,42,52,62,72,83,93,103,113,12The following is the brief example which is calculating min, max, and mean for each partitions.
REFERENCE ASSEMBLY [ExtR];DECLARE @SrcFile string = @"/sampledat/test01.csv";DECLARE @DstFile string = @"/sampledat/output01.txt";DECLARE @myRScript = @"outputToUSQL <- data.frame( CalcType = c(""min"", ""max"", ""mean""), CalcValue = c(min(inputFromUSQL$Value),max(inputFromUSQL$Value),mean(inputFromUSQL$Value) ))";@ExtendedData = EXTRACT PartitionId int, Value int FROM @SrcFile USING Extractors.Csv();@RScriptOutput = REDUCE @ExtendedData ON PartitionId PRODUCE PartitionId int, CalcType string, CalcValue double READONLY PartitionId USING new Extension.R.Reducer(command:@myRScript,rReturnType:"dataframe",stringsAsFactors:false);OUTPUT @RScriptOutput TO @DstFile USING Outputters.Tsv();The following screenshot is the result of this U-SQL.
Each partition is executed independently in parallel, and all results are collected by REDUCE operation.
Note that you have to specify ON {partition keys (multiple)} or ALL when you’re using REDUCE clause. (You cannot skip ON / ALL.)
So if you don’t need partitioning, you specify the pseudo partition (one same partition for all raw) like the following script.
REFERENCE ASSEMBLY [ExtR];DECLARE @SrcFile string = @"/sampledat/test01.csv";DECLARE @DstFile string = @"/sampledat/output01.txt";DECLARE @myRScript = @"outputToUSQL <- data.frame( CalcType = c(""min"", ""max"", ""mean""), CalcValue = c(min(inputFromUSQL$Value),max(inputFromUSQL$Value),mean(inputFromUSQL$Value) ))";@ExtendedData = EXTRACT SomeId int, Value int FROM @SrcFile USING Extractors.Csv();@ExtendedData2 = SELECT 0 AS Par, // pseudo partition * FROM @ExtendedData;@RScriptOutput = REDUCE @ExtendedData2 ON Par PRODUCE Par int, CalcType string, CalcValue double READONLY Par USING new Extension.R.Reducer(command:@myRScript,rReturnType:"dataframe",stringsAsFactors:false);OUTPUT @RScriptOutput TO @DstFile USING Outputters.Tsv();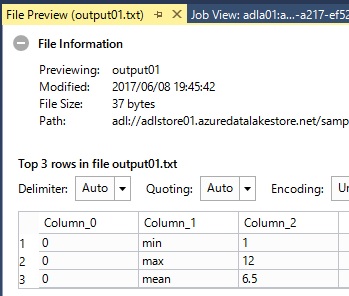
Installing packages
There are default supported packages in R extension, but you can install extra packages if needed. (See here for the default packages of R extension. It’s also including RevoScaleR package.)
First you download the package file (.zip, .tar.gz, etc) using your local R console. Now here we download the famous svm package “e1071”. (We assume the file name is e1071_1.6-8.tar.gz.)
download.packages("e1071", destdir="C:\tmp")Next you upload this package file to the folder in your ADLS (Data Lake Store).
After that, you can specify this package file in your U-SQL and you can install this package in your R script as follows.
REFERENCE ASSEMBLY [ExtR];DEPLOY RESOURCE @"/sampledat/e1071_1.6-8.tar.gz";DECLARE @SrcFile string = @"/sampledat/iris.csv";DECLARE @DstFile string = @"/sampledat/output03.txt";DECLARE @myRScript = @"install.packages('e1071_1.6-8.tar.gz', repos = NULL) # installing packagelibrary(e1071) # loading package# something to analyze !# (Later we'll create the code here ...)data.frame(Res = c(""result1"", ""result2""))";@InputData = EXTRACT SepalLength double,SepalWidth double,PetalLength double,PetalWidth double,Species string FROM @SrcFile USING Extractors.Csv();@ExtendedData = SELECT 0 AS Par, * FROM @InputData;@RScriptOutput = REDUCE @ExtendedData ON Par PRODUCE Par int, Res string READONLY Par USING new Extension.R.Reducer(command:@myRScript,rReturnType:"dataframe",stringsAsFactors:false);OUTPUT @RScriptOutput TO @DstFile USING Outputters.Tsv();Loading R data
In the real scenario, you might use the pre-trained model for predictions. In such a case, you can create the trained model (R objects) beforehand, and you can load these R objects on your R script in U-SQL.
First you create the trained model using the following script in your local environment. The file “model.rda” will be saved in your local file system.
(Here we’re using script for saving, but you can also use RStudio IDE.)
library(e1071)inputCSV <- read.csv( file = "C:\tmp\iris_train.csv", col.names = c("SepalLength","SepalWidth","PetalLength","PetalWidth","Species"))mymodel <- svm( Species~., data=inputCSV, probability = T)save(mymodel, file = "C:\tmp\model.rda")Note that we assume our training data (iris data) is as follows. (It’s the same as U-SQL extension sample files…) :
iris_train.csv
5.1,3.5,1.4,0.2,setosa7,3.2,4.7,1.4,versicolor6.3,3.3,6,2.5,virginica4.9,3,1.4,0.2,setosa...Then you upload this generated model (model.rda file) on the folder in your ADLS (Data Lake Store).
Now it’s ready, and let’s go jump into the U-SQL.
See the following R script in U-SQL.
This R script is loading the previous pre-trained model (model.rda). By this, you can use pre-trained R object “mymodel” in your R script.
All you have to do is to predict your input data with this model object.
REFERENCE ASSEMBLY [ExtR];DEPLOY RESOURCE @"/sampledat/e1071_1.6-8.tar.gz";DEPLOY RESOURCE @"/sampledat/model.rda";DECLARE @SrcFile string = @"/sampledat/iris.csv";DECLARE @DstFile string = @"/sampledat/output03.txt";DECLARE @myRScript = @"install.packages('e1071_1.6-8.tar.gz', repos = NULL)library(e1071)load(""model.rda"")pred <- predict( mymodel, inputFromUSQL, probability = T)prob <- attr(pred, ""probabilities"")result <- data.frame(prob, stringsAsFactors = FALSE)result$answer <- inputFromUSQL$SpeciesoutputToUSQL <- result";@InputData = EXTRACT SepalLength double,SepalWidth double,PetalLength double,PetalWidth double,Species string FROM @SrcFile USING Extractors.Csv();@ExtendedData = SELECT 0 AS Par, * FROM @InputData;@RScriptOutput = REDUCE @ExtendedData ON Par PRODUCE Par int, setosa double, versicolor double, virginica double, answer string READONLY Par USING new Extension.R.Reducer(command:@myRScript,rReturnType:"dataframe",stringsAsFactors:false);OUTPUT @RScriptOutput TO @DstFile USING Outputters.Tsv();
[Reference] Tutorial: Get started with extending U-SQL with R
https://docs.microsoft.com/en-us/azure/data-lake-analytics/data-lake-analytics-u-sql-r-extensions
Categories: Uncategorized

Thanks for great information.
LikeLike
Thank you!
Finally some more practical examples on the R-integration!
LikeLiked by 1 person
By the way; Instead of loading the models though DELPOY/load, is it possible to access the data lake directly from the r script run by ADLA?
LikeLike
No, you cannot. You must load by “DEPLOY RESOURCE” for accessing files. (Except for “inputFromUSQL” data frame.)
LikeLike
How can I gain access to the processing power of ADLA from RStudio directly. The workflow would consist in (a) connecting to the ADLA, (b) using a library to query the ADLA and do parallel processing with it, (c) retrieving the results. I find it extremely cumbersome that R must be inlined into U-SQL, and would prefer to avoid it.
LikeLike
Hi Tsuyoshi, do you know if one can use two rowsets at the same time in the R Script? That is, having two “inputFromUSQL”.
LikeLike
Hi Adeoluwa-san, I’m so sorry, but I haven’t tried for multiple rowsets. But I think it might be impossible, because the official document says as follows.
https://docs.microsoft.com/en-us/u-sql/statements-and-expressions/table-valued-function-expression
“A U-SQL TVF can either return a single rowset or multiple rowsets. If it returns multiple rowsets it can only be assigned to rowset variables and cannot be called in a FROM clause, set expressions, or OUTPUT.”
LikeLike