
The dataset in Apache Spark, such as DataFrame or RDD, is distributed and partitioned into multiple chunks on the bottom. Each concurrent task in Apache Spark runs on each partition.
Even when you read data in Apache Spark, it’s also parallelized for each partitions by execution plan.
On the other hand, data in Azure Cosmos DB is also chunked into partitions. As I explained in my early post “Azure Cosmos DB – How it works“, your query with partition key is optimized to run only on the target partition. When you run query without partition key, the query eventually runs on all partitions.
These both partition’s mechanism are transparently applied and you can take these advantages without any additional tasks. You just write your program code without knowing any details of partitions.
Note : In Apache Spark, you can see the differences by partitions using df.rdd.mapPartitions(). For Azure Cosmos DB, please see my early post for how the partition is determined. (It is determined by hash and then you can identify the partition of data by partition key value.)
Especially when you collaborate Apache Spark and Cosmos DB with official Azure Cosmos DB Connector for Apache Spark (azure-cosmosdb-spark connector), these partition mechanism will work much better and together !
(See Github repo for details about azure-cosmosdb-spark connector.)
How it’s optimized inside Connector ?
Now let’s briefly see how it works behind connector. (I tracked the following behavior with the connector version 1.3.4.)
Here we consider we read massive data from Cosmos DB using azure-cosmosdb-spark connector as follows.
config = { "Endpoint" : "https://mytest01.documents.azure.com:443/", "Masterkey" : "cexoXTla2a...", "Database" : "testdb01", "preferredRegions" : "East US", "Collection" : "collection01",}df = spark.read.format("com.microsoft.azure.cosmosdb.spark").options(**config).load()With this 2 lines of code, the connector will do the following internally : (See “Azure Cosmos DB Spark Connector User Guide” in Wiki.)
- The connector obtains the Cosmos DB partition map.
- The connector determines partitions (parallelism) for Spark DataFrame along with the required Cosmos DB partition.
- Each Spark partition directly extracts the data from each Cosmos DB partition.
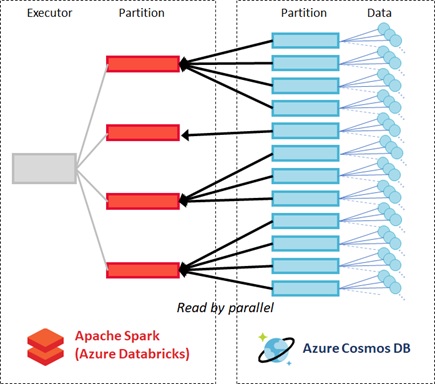
Now let’s see the following illustrated.
If it’s available, the connector configure the same number of partitions in Spark DataFrame and the read operation is horizontally scaled (by data parallel) using both Spark partitions and Cosmos DB partitions.
If the number of required Cosmos DB partition were only 1, the only single partition in Spark DataFrame would work.

Note : Here I used Azure Databricks for tracking, but you can also use built-in Apache Spark in Cosmos DB (now in Preview).
What if there’s not enough space for partitions in Spark ? For instance, what if there’s few worker nodes and few cores in Spark ? Or what if massively large number of partitions exist in Cosmos DB ?
Even so, all partitions in Cosmos DB are mapped into the available partitions in Spark. All data in one Cosmos DB partition are mapped into the same partition in Spark DataFrame. (i.e, Data in one Cosmos DB partition is never divided into the multiple partitions in Spark.) In this case, you could increase the read performance by increasing workers in Apache Spark.
See the following illustrated. The relationship is “one to many”.
It can also consumed in parallel with change feed, however, be care for bulk write operation, since it’s not one-to-one (or one-to-many) direct partition communication unlike read operation.
In such case, please consider to use bulk executor. (When you call bulk import in azure-cosmosdb-spark connector, set BulkImport as true in connector’s config.)
Categories: Uncategorized

2 replies»