
Azure HDInsight is based on Hortonworks (see here) and the 1st party managed Hadoop offering in Microsoft Azure. (i.e, You can use Azure support service even for asking about this Hadoop offering.)
You can quickly start and see how LLAP is different with regular Hive (on Tez container) using this cloud managed cluster. I show you this brief steps in this post.
As you know, Apache Hive is popular component for massive query and analysis built on top of Apache Hadoop and inherently based on batch architecture. Hive LLAP (Live Long And Process, or Low Latency Analytical Processing) uses in-memory caching for Hive execution to speed up for realizing MPP performance (near real-time), while it maintains compatibility with existing Hive SQL and tools.
In this post I don’t say much about Hive LLAP architecture, but you can refer “LLAP – a one-page architecture overview (Hortonworks)” or “Hive LLAP deep dive (Hortonworks)“.
There are a lot of components and combination in speed-layer architecture, and on the coming “Azure Advanced Analytics 1-day seminar” (24th Apr 2019, Japan), we’ll show you a variety of real-time techniques, such as Apache Kafka, Storm, structured streaming on Databricks (Apache Spark & AI) and other alternatives (Event Hub, Stream Analytics, etc) as well as advanced datastore and data warehouse on Microsoft Azure with a lot of demos.
Since we won’t have much time to talk about LLAP in this seminar, I show you this (Apache Hive LLAP on Azure HDInsight) here in this post.
Quickstart for Your Hadoop Cluster with Managed Service
You can launch Hadoop cluster in which Hive LLAP is enabled, with just a few steps using managed service “Azure HDInsight”.
First you must prepare Azure storage account (blob storage) on Azure Portal. All Hadoop meta files (such as logs, histories, and settings) and database files would be stored in this blob storage.
Next create new HDInsight resource on Azure Portal and just provide the following settings in the creation wizard. (Use “Custom” settings instead of “Quick Create” to specify details.)
- Select “Interactive Query” (or Interactive SQL) for cluster type.
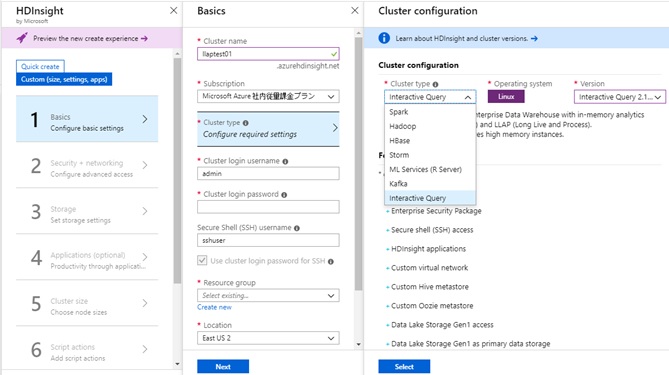
- Specify previously prepared blob storage for meta storage.
- Set cluster size to meet your performance requirements and costs.
You can also use low-cost workers (such as A2M v2 instances) for test purpose, but here we use D13 v2 (x 3 workers), because we want to accelerate LLAP by SSD cache-enabled instances.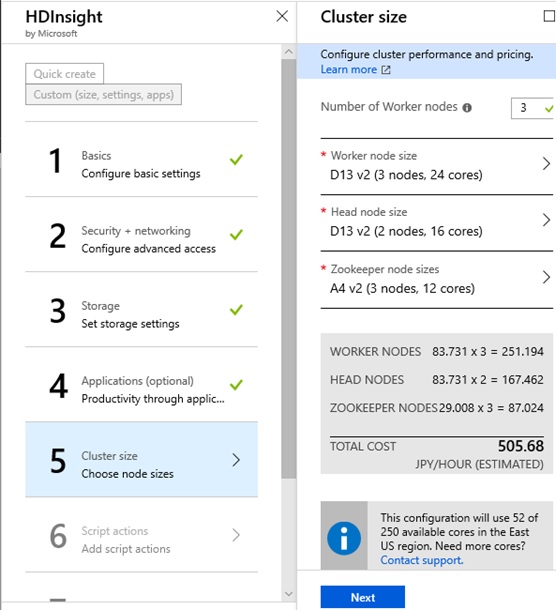
Run Benchmarks – See Performance Difference Yourself
The key difference between LLAP and Tez container (non LLAP) is performance. Now we’ll compare these 2 performance on generated cluster.
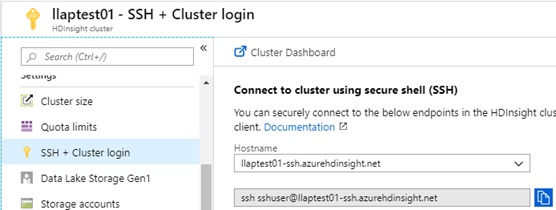
Click “SSH + Cluster login” menu on generated HDInsight resource blade in Azure Portal, and copy primary headnode’s hostname and username (“sshuser”).
Login to your cluster’s headnode using SSH client with these hostname and username.
After logging-in, clone following Hortonworks repository for benchmarks.
git clone https://github.com/hortonworks/hive-testbench.gitcd hive-testbench/Build benchmark scripts with the following command.
./tpcds-build.shNext, open tpcds-setup.sh file in an editor.
vi tpcds-setup.shChange the following line (hive command settings) in tpcds-setup.sh file to match with your HDInsight environment.
Note that the following ‘hn0-llapte’ must be your headnode hostname. (Type ‘hostname‘ on your headnode.)
...# HIVE="beeline -n hive -u 'jdbc:hive2://localhost:2181/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=hiveserver2?tez.queue.name=default' "HIVE="beeline -n hive -u 'jdbc:hive2://hn0-llapte:10001/;transportMode=http' "...And run the following command in order to generate data at scale factor 100 (100 GB). It takes a while and please be patient to wait completion …
By running this command, a database “tpcds_bin_partitioned_orc_100” (including tables) is generated and data is saved as ORC file format.
Note : If you want to trace all outputs, please set the following environment variable and run.export DEBUG_SCRIPT=X
./tpcds-setup.sh 100Now it’s ready to test your Hive cluster.
Start Apache Beeline client with the following command, and enter into beeline console. (Note that hive CLI is deprecated, then we use beeline.)
Note : When you want to quit beeline, run “!quit“.
For hive commands and SQLs, see “Simple Hive Cheat Sheet for SQL Users (Hortonworks)“.
cd sample-queries-tpcdsbeeline -u 'jdbc:hive2://hn0-llapte:10001/;transportMode=http'In beeline console, run query55.sql (one of benchmarking SQL scripts) with LLAP mode !
(Note that LLAP is used by default, then you don’t need to set the following “hive.llap.execution.mode” first time.)
beeline> use tpcds_bin_partitioned_orc_100;beeline> set hive.llap.execution.mode=all;beeline> !run query55.sqlI show you query55.sql below. (See here in the original repository.)
This script (query) executes many of Maps and Reduces.
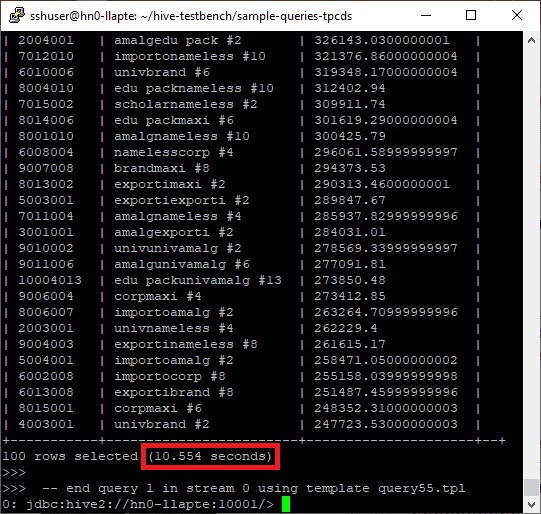
-- start query 1 in stream 0 using template query55.tpl and seed 2031708268select i_brand_id brand_id, i_brand brand,sum(ss_ext_sales_price) ext_price from date_dim, store_sales, item where d_date_sk = ss_sold_date_skand ss_item_sk = i_item_skand i_manager_id=36and d_moy=12and d_year=2001 group by i_brand, i_brand_id order by ext_price desc, i_brand_idlimit 100 ;-- end query 1 in stream 0 using template query55.tplYou could see it runs on LLAP mode in the result’s outputs as follows.
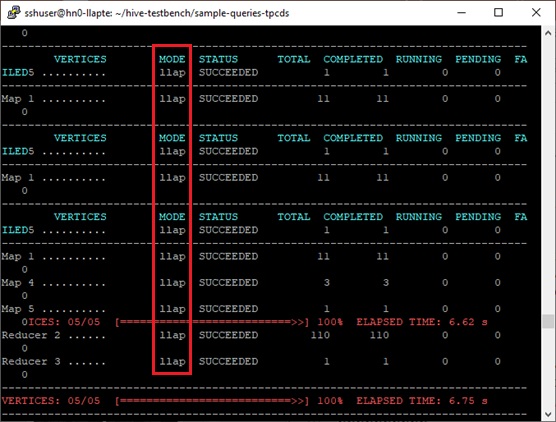
With my cluster (D13 v2, 3 workers), you will find it takes 10.554 seconds as follows.
Next we run the same query without LLAP as follows.
By setting hive.llap.execution.mode=none, it runs query on container (on Tez) mode instead.
Let’s compare with the previous results.
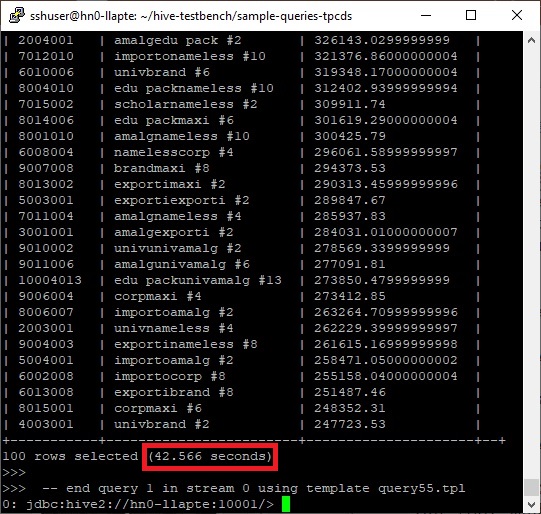
beeline> set hive.llap.execution.mode=none;beeline> !run query55.sqlNow you will find that it surely runs on container mode and it takes 42.566 seconds for the same query as follows.
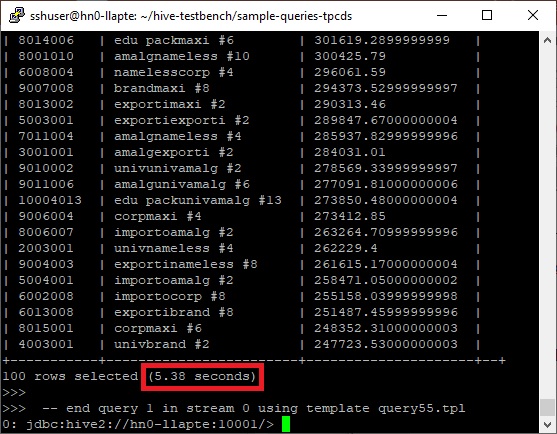
Again, change mode into LLAP and run the same script.
beeline> set hive.llap.execution.mode=all;beeline> !run query55.sqlNow you will find it’s more performant (5.38 seconds) as follows.
Here I described a brief outline for benchmarks on HDInsight, but you can refer “Azure HDInsight Performance Benchmarking: Interactive Query, Spark and Presto (Azure blog)” for much about performance consideration on Azure HDInsight.
Building Applications – Connect from Your Familiar Clients
In the practical application development, you can also use JDBC / ODBC and run LLAP-enabled Hive query.
As official document (see here) says, the port for both ODBC and JDBC (HiveServer2) is public by default. Then you don’t need to configure VNet and you can soon connect to the previous database (tpcds_bin_partitioned_orc_100) and run SQL with your familiar client, such as Excel, Power BI, etc.
Here I don’t describe about steps, but see the following official documents for these walkthroughs.
- Connect with ODBC driver from Microsoft Excel
- Connect with ODBC driver from Power BI
- Connect with JDBC driver from SQuirreL SQL client
Learn more about big data analytics on Azure in “Azure Advanced Analytics 1-day seminar” (24th Apr 2019, Japan) !
Categories: Uncategorized
