
A lot of AI companies have their own in-house GPU machines. While they want to reuse these resources, they also need a variety of other hardware depending on workloads.
For instance, they will usually use their own in-house hardware, but some workloads will need more powerful GPU (such as, NVIDIA A100) on cloud. Some workloads – such as, hyper-parameter searches – might need a lot of multiple cloud computes for massive distribution.
In other cases, they would perform the model creation in-house, but model hosting (serving) on cloud.
With Azure Arc-enabled Machine Learning, you can bring AML open architecture into the existing external resources – such as, on-premise machines or 3rd party platforms (EKS, GKE, etc).
Data science team can operate ML jobs on any platforms anywhere, with Azure Machine Learning consistent manners.
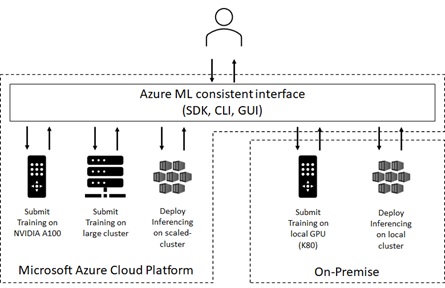
In this post, I’ll briefly show you what you can do and how you can use with Arc-enabled Machine Learning.
First, Connect Your k8s cluster via Azure Arc
First of all, you must configure Azure Arc enabled Kubernetes on-premise (running K3S, KIND, etc) or on 3rd party cloud.
In order to run Arc-enabled Machine Learning later, use machines with more than 4 CPUs, since Arc-enabled ML requires enough resources.
In this post, I assume that we run KIND (Kubernetes in Docker) cluster on Ubuntu 20.04 in a single on-premise node. (For test purpose, I have used Standard D3 v2 virtual machine in Azure, which has 4 CPUs and 14 GB memory.)
# Install dockercurl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -sudo add-apt-repository "deb [arch=amd64] https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable"sudo apt-get -y updatesudo apt-get -y install docker-cesudo usermod -aG docker $USER###### logout and login again to take effect for permission###### Download Kindcurl -Lo ./kind https://kind.sigs.k8s.io/dl/v0.11.1/kind-linux-amd64chmod +x ./kind# Install and run Kind (Kubernetes) cluster./kind create clusterBy the above installation, kubeconfig (~/.kube/config) will be automatically generated in your working directory.
In this connected environment, please register your local cluster as an Arc-enabled Kubernetes resource in Azure by running the following commands.
# Install Helmcurl https://baltocdn.com/helm/signing.asc | sudo apt-key add -sudo apt-get install apt-transport-https --yesecho "deb https://baltocdn.com/helm/stable/debian/ all main" | sudo tee /etc/apt/sources.list.d/helm-stable-debian.listsudo apt-get updatesudo apt-get install helm# Install Azure CLIcurl -sL https://aka.ms/InstallAzureCLIDeb | sudo bash# Install connectedk8s extension in CLIaz extension add --name connectedk8s# Login to your Azure subscriptionaz loginaz account set --subscription {SubscriptionID}# Register providers# (Do once in your subscription. It will take a while...)az provider register --namespace Microsoft.Kubernetesaz provider register --namespace Microsoft.KubernetesConfigurationaz provider register --namespace Microsoft.ExtendedLocation# Create a resource groupaz group create --name MLTest --location EastUS# Connect local cluster (in kubeconfig) to Azure resourceaz connectedk8s connect --name MLTest1 --resource-group MLTestNow your Arc-enabled Kubernetes is ready.
For beginners, this post will help you to understand how Arc-enabled Kubernetes can be connected remotely.
Install Arc-Enabled ML extension on Your Cluster
Next, install cluster extension for Arc enabled Machine Learning (Microsoft.AzureML.Kubernetes) on this cluster.
# Add Kubernetes extensionaz extension add --name k8s-extension# Install Arc-Enabled ML extension in clusteraz k8s-extension create --name arcml-extension \ --extension-type Microsoft.AzureML.Kubernetes \ --cluster-type connectedClusters \ --cluster-name MLTest1 \ --config enableTraining=True \ --resource-group MLTest \ --scope clusterNote : (This is not needed for the latest extension.)
For now (July 2021), specify the following version option to run a training job on-premise KIND cluster. (This version will soon be released.)Otherwise, the submitted run in AML will get stuck with “Queued” status.az k8s-extension create --name arcml-extension \ --extension-type Microsoft.AzureML.Kubernetes \ --configuration-settings enableTraining=True \ --cluster-type connectedClusters \ --cluster-name MLTest1 \ --resource-group MLTest \ --scope cluster \ --release-train staging --version 1.0.48
After running above command, please run as follows and check whether the installation is succeeded.
az k8s-extension show --name arcml-extension \ --cluster-type connectedClusters \ --cluster-name MLTest1 \ --resource-group MLTestWhen the installation is completed, you can see the following pods correctly running in your local cluster.
The above command (with enableTraining=True setting) will also generate Azure Service Bus and Azure Relay resource in Azure. The communications between AML workspace (cloud) and your cluster (local) will be relayed by these resources using the outbound connection.
# Install kubectl commandcurl -LO "https://dl.k8s.io/release/$(curl -L -s https://dl.k8s.io/release/stable.txt)/bin/linux/amd64/kubectl"sudo install -o root -g root -m 0755 kubectl /usr/local/bin/kubectl# List pods in azureml namespace# (Run "kubectl get all" instead for listing all other resources)kubectl get pod --namespace azuremlNAME READY STATUSaml-operator-6bcd789c49-lzmhw 2/2 Runningamlarc-compute-kube-state-metrics... 1/1 Runningcluster-status-reporter-7b7b6c65b... 1/1 Runningfluent-bit-xv7b7 1/1 Runningframeworkcontroller-0 1/1 Runninggateway-5667747ccb-5rxvd 1/1 Runningmetrics-controller-manager-67688d... 2/2 Runningnfd-master-6f4b4b4554-vpsmg1/1 Runningnfd-worker-mzz5j 2/2 Runningprom-operator-7bc87d97dc-vxkxt 2/2 Runningprometheus-prom-prometheus-0 3/3 Runningrelayserver-7bb77d9479-4rxhd 1/1 Runningrelayserver-7bb77d9479-qw6bv 1/1 RunningIf your pods are not correctly running, please see pod status or container logs, and fix errors.
# Show pod detailskubectl describe pods {PodName} \ --namespace azureml# Show container logskubectl logs {PodName} \ --container="{ContainerName}" \ --namespace azuremlAttach Cluster in ML Workspace
Now let’s create Azure Machine Learning resource (ML workspace) in Azure Portal.
(The following grant settings is not required for the latest ML workspace.)
Next we grant permissions for Arc-enabled cluster’s actions to your generated ML workspace (ML resource).Once you have generated Machine Learning workspace in Azure, you can get system-assigned managed identity (which is automatically generated) for this resource.In Azure Active Directory tenant in your subscription, you can search and view this identity. (See below.) Now please copy object id of this managed identity.
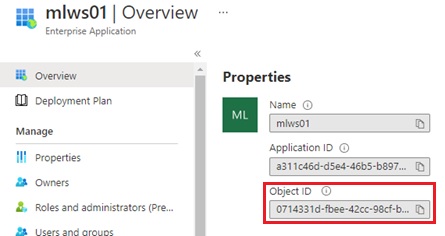
Create a custom role for Arc-enabled cluster’s actions as follows. In this example (below), I have granted permissions for all cluster’s actions.
# Create a role for Arc-enabled kubernetes actionsaz role definition create --role-definition '{ "Name": "Custom Role for Arc Kubernetes Actions", "Description": "Auth for connected clusters", "Actions": ["Microsoft.Kubernetes/connectedClusters/*"], "DataActions": [], "NotDataActions": [], "AssignableScopes": ["/subscriptions/{SubscriptionID}"]}'When it displays the output result, please copy the name of this custom role. In this example (below), I assume that the following 394b877b-315c-477e-8b74-ff765b6590d0 is the name of this custom role.
{ "assignableScopes": ["/subscriptions/b3ae1c15..." ], "description": "Auth for connected clusters", "id": "/subscriptions/b3ae1c15.../providers/Microsoft.Authorization/roleDefinitions/394b877b-315c-477e-8b74-ff765b6590d0", "name": "394b877b-315c-477e-8b74-ff765b6590d0", ...}Using this role name, assign this role to your ML workspace (Azure AD managed identity) as follows.Please replace the following {ObjectId} with the one of ML resource’s managed identity.
az role assignment create \ --role {RoleName} \ --assignee {ObjectId} \ --scope /subscriptions/{SubscriptionID}Open Azure Machine Learning studio UI (https://ml.azure.com/).
Click “Compute” tab in left navigation and attach this Arc-enabled cluster on “Attached computes” tab as follows.
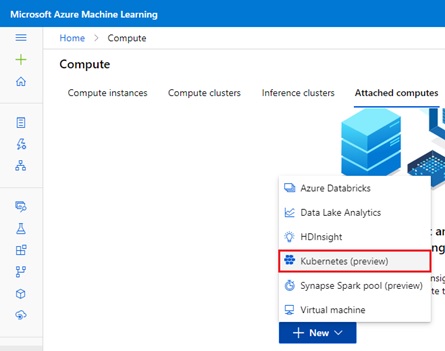
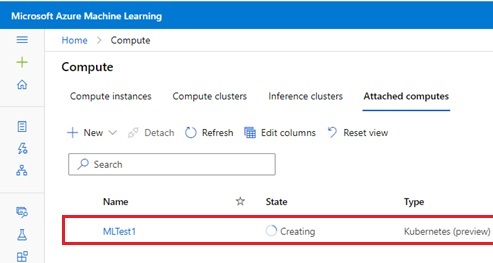
Note : You can also attach Kubernetes compute with Azure CLI as follows.
az ml compute attach
--resource-id {connected-cluster-resource-id} \
--name {compute-target-name} \
--file {compute-target-config-YAML}Note : If attachment fails, please wait a while until Arc-enabled ML is provisioned.
Run ML Workload on Arc-enabled Cluster
Now let’s run this tutorial (training script) on this on-premise cluster.
To run your script on this attached cluster, you should just specify “azureml:{attached compute name}” for compute name in YAML as follows. (Others are same as cloud jobs.)
az ml job create --file train_experiment_job.yml \ --resource-group $my_resource_group \ --workspace-name $my_workspacetrain_experiment_job.yml (YAML)
$schema: https://azuremlschemas.azureedge.net/latest/commandJob.schema.jsoncode: scriptcommand: >- python train01.py --data_folder ${{inputs.mnist_tf}}inputs: mnist_tf:type: uri_folderpath: azureml:mnist_tfrecords_data@latestenvironment: azureml:test-remote-cpu-env-for-logging@latestcompute: azureml:MLTest1display_name: tf_remote_experiment02experiment_name: tf_remote_experiment02description: This is exampleAs the following picture shows, the submitted script (train01.py) will run on-premise cluster.
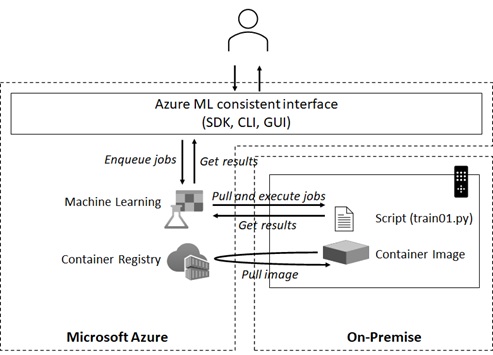
The cloud AML workspace will collect and store the generated model, logs, and metrics for the job running on-premise.
You can view and extract these artifacts in history on cloud, anytime you need.
While you can use data asset in cloud AML workspace, you can also use on-premise data in Arc-enabled ML jobs. Especially, you can mount NFS volume on-premise and use data in that volume.
For details about NFS mount settings, see this document in official GitHub repository.
Once you have configured for NFS mount, you can run a job using data on shared local NFS volume.
For instance, when your training data (e.g, data.csv) exists in local NFS volume, you can mount this volume as the path /example-share in pods and specify this path in Python script’s arguments.
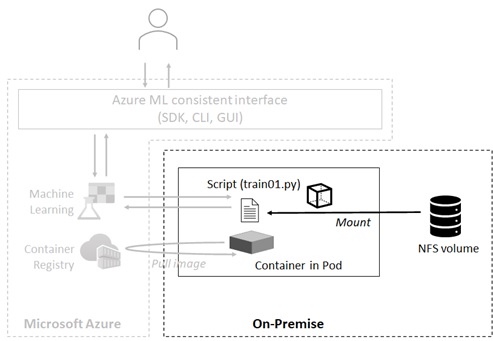
Currently these 2 options (cloud and NFS volume) for data access are available in Arc-enabled ML, but more options will come in the future.
As you saw above, you can automate all jobs in AML, even when it runs on-premise.
You can also run a variety of AML value-added features on-premise, such as, hyper-parameter tuning or ML pipeline, not depending on specific framework. (See here about these features.)
Run Pipeline with AML Designer on Arc-enabled ML
You can also run ML pipeline built within Azure Machine Learning Designer (no-code experience), even in Arc-enabled ML jobs.
For instance, please select built-in “Automobile Price Prediction” example in AML Designer as follows. (This pipeline will generate and evaluate the model for predicting the price of used-cars.)
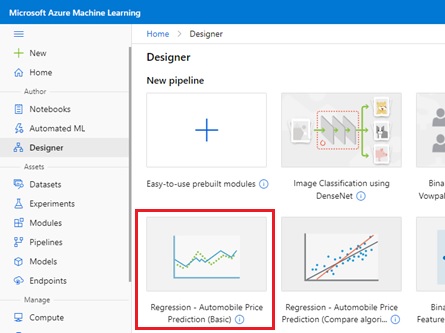
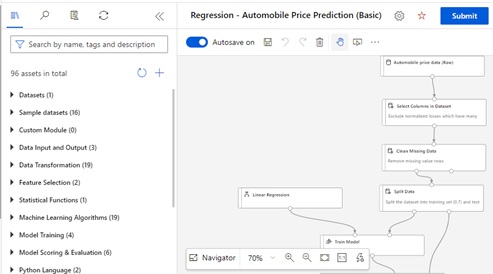
In order to run this pipeline on your own Kubernetes cluster (on-premise), just select and run on the attached arc-enabled resource.
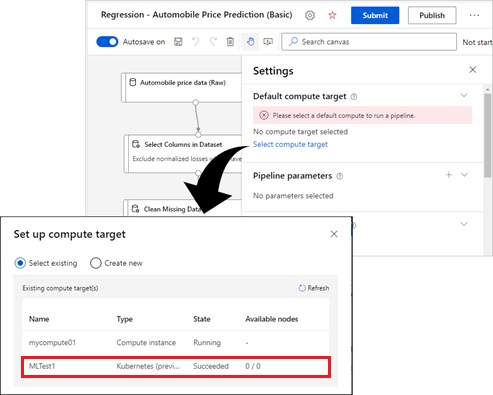
Inferencing (Serving) on Arc-enabled ML
You can also deploy model (for serving) on Arc-enabled on-premise compute.
To run AML deployment on your own Kubernetes, please specify enableInference=True in Arc ML extension’s configuration as follows.
az k8s-extension create --name arcml-extension \ --extension-type Microsoft.AzureML.Kubernetes \ --cluster-type connectedClusters \ --cluster-name MLTest1 \ --config enableInference=True inferenceRouterServiceType=nodePort allowInsecureConnections=True \ --resource-group MLTest \ --scope clusterNote : For test purpose, SSL is not enabled above. (Please make sure to enable SSL in production.)
Same as training jobs, you should attach your on-premise Kubernetes before deployment.
Now you can deploy your model on this Kubernetes as usual with AML CLI v2 and YAML configuration.
For instance, I have run this notebook on tutorial.
To create AML endpoint on your Kubernetes (on-premise Kubernetes), please specify your attached Kubernetes name in compute entity in YAML as follows.
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineEndpoint.schema.jsonname: my-mnist-endpointcompute: azureml:MLTest1auth_mode: keyTo create a deployment on your Kubernetes, please specify the configuration as follows.
- Set “
type: kubernetes“. - Use
defaultinstancetypeforinstance_typeentry. (Also I have removedinstance_countentry.)
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineDeployment.schema.jsonname: my-mnist-deployment-v1type: kubernetesendpoint_name: my-mnist-endpointmodel: azureml:mnist_model_test:1code_configuration: code: ./ scoring_script: score.pyenvironment: conda_file: 08_conda_env.yml image: mcr.microsoft.com/azureml/openmpi3.1.2-ubuntu18.04instance_type: defaultinstancetypeI note that your deployment runs on-premise Ubuntu machine, in which Kubernetes is running. (The endpoint address will then also be internal IP address.)
In order to check whether your endpoint is correctly running, please login to on-premise Ubuntu machine (in which Kubernetes is running) and invoke your web service with curl command as follows.
curl -v -i -X POST -H "Content-Type:application/json" -H "Authorization: Bearer <API KEY>" -d '<POST DATA>' <SCORE URI>Note : Following is an example.
curl -v -i -X POST -H "Content-Type:application/json" -H "Authorization: Bearer KdWmUttGyl7i2hvWLQdj5l....." -d '{"data" : [[...]]}' http://172.18.0.2:31100/api/v1/endpoint/my-mnist-endpoint/score
As you saw above, you can easily build and integrate MLOps for multiple environments (such as, on-premise, EKS, or GKE) in consistent manner with Azure Machine Learning.
Categories: Uncategorized

2 replies»