
For the purpose of your beginning of machine learning, here I show you the fundamental mathematics behind regression with several examples.
Table of Contents
- Introduction to Maximum Likelihood Estimation (MLE)
- Interpretation of MLE into Information Theory
- Regression Family (Logistic, Linear, Poisson, Gamma)
- Link Functions
- Evaluation Metrics
- Other Methods for Regression (Further Learning …)
In this post, I’ll focus on parametric regression, which is a very basic method for regression.
There exist 2 main design choices for parametric regression as follows.
- What surrogate loss should be used to measure the difference between actual distribution and estimated distribution ?
- Which model is used to represent the distribution ?
For the former one, we apply (log) likelihood to measure the difference between actual distribution and estimated distribution. In the chapter 1 “Introduction to Maximum Likelihood Estimation”, I’ll explain the background math idea of this method. In the chapter 2 “Interpretation of MLE with Information Theory”, I’ll dig into MLE from a perspective of information theory.
For the latter part, I’ll explain a variety of models used today, in the chapter 3 “Regression Family”. The chapter 4 “Link Functions” will follow the other consideration for model designing.
There also exist other methods (such as, Bayesian inference, non-parametric methods, …) for solving practical problems. At the last part of this post (the chapter 6 “Other Methods for Regression”), I’ll introduce you the brief outline of these advanced methods
Mathematics behind ideas is very important to know exactly what the machine learning is. From this perspective, this post will explain mathematical ideas behind regression, but I’ll keep writing without difficult descriptions or complicated proofs.
I’ll also show you example code using R scripts, but even when you’re not familiar with R, it will be easy to understand, because I’ll keep my source code as simple as possible.
This post also gives you various insights in machine learning for the related topics.
1. Introduction to Maximum Likelihood Estimation (MLE)
One of primitive methods to find the optimal form of regression is to find parameters which maximizes the probability.
Maximum likelihood estimation (shortly, MLE) is based on this idea.
In this post, I’ll use several models (GLM regression family), each of which depends on specific problem respectively. But, regardless of the selected model, the following method (i.e, MLE) is commonly applied to solve regression problems through this post.
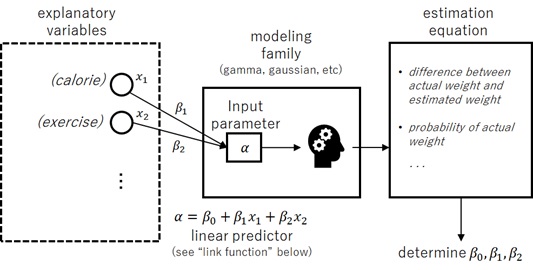
1. First, we should choose the appropriate statistical model (e.g, normal distribution, binomial distribution, Gamma distribution, etc) depending on each problem.
For instance, suppose, we want to predict human’s weight in some group, and we suppose that it depends on their daily calorie intake and daily amount of exercise.
In this case, we can apply linear regression model, because we can expect that the human weight will follow the normal distribution (Gaussian distribution).
In this example, the human’s weight is called a response variable (or label), and human’s daily calorie intake and daily amount of exercise are called explanatory variables (or features). Next I’ll give the expression of response variable using these explanatory variables.
2. The selected model (here, normal distribution) will have the corresponding parameters.
We suppose that these parameters of distribution depends on explanatory variables, and we then give the expression of these parameters using the formula of explanatory variables.
In above example, the Gaussian distribution (normal distribution) 
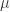
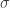
We now assume that 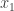
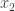



Here I assume that
3. Finally we estimate 


In above example, suppose, we have observed all human’s weights 


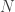
For some fixed observation 





By multiplying all these probabilities by 
We can then estimate the optimal
This method to maximize probability is called maximum likelihood estimation (MLE).
MLE is not the only thing to estimate the optimal parameters.
For instance, the ordinary least squares (OLS) is another estimation method to find parameters to minimize the difference between actual (observed) values 

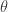

Note : Or use mean squared error (shortly, MSE), which is the mean
, instead of the sum.
As I’ll show you later in this post, the solution to minimize a quadratic loss (or MSE) is equivalent to the solution to minimize likelihood (i.e, MLE) under Gaussian distribution. (For details, see linear regression in the following chapter 3.)
Note : Instead of a quadratic loss function, the following absolute loss function (or L1 loss function) can also be used to minimize the the difference between actual (observed) values and the estimated values. :
It’s known that minimizing a quadratic loss gives the mean for training samples, while an absolute loss gives the median.

Sometimes MLE is ironically called “frequentist” approach, and you should remember that MLE is not always the best method for fitting in the given regression problems.
In the last part of this post, I’ll also discuss the shortcomings of MLE and show you other advanced alternatives.
2. Interpretation of MLE into Information Theory
There’s a close relation between the likelihood solution and the solution obtained from the principle of entropy.
Here I briefly show you how it’s related.
Note : You can skip this chapter, if you don’t have any interest to information theory behind methods.
Suppose, 


In this assumption, the number of actual occurrence 

Maximizing 

This formula 
This shows that minimizing cross-entropy loss is equivalent to maximizing the log likelihood.
Note : In neural networks, a cross-entropy function is often used as a loss function to quantify the difference between true values and estimated values. (The loss should then be minimized to optimize neural networks.)
According to information theory, the following 
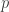

And the following 

In information theory, it’s known that the stable probability distribution (i.e, randomness) leads to large entropy and you can then find optimal distribution by finding distribution to maximize entropy (which is called maximum entropy principle).
For instance, the continuous distribution to maximize entropy is known to be Gaussian distribution. A lot of possibilities in natural state can be written by exponential formula – a set of which distributions are called exponential family (see this Wikipedia) -, and these distributions also have maximum entropy in some constraints.
On contrary, KL divergence (or relative entropy) is often used as a distance of distributions between 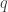


As you can easily see, maximizing entropy 
Note : For these background behind information theory, see chapter 1.6 in “Pattern Recognition and Machine Learning” (Christopher M. Bishop, Microsoft).
As you can also see, 

Here I don’t go into details, but it’s also known that maximum likelihood on exponential family is a dual problem of maximizing entropy, subject to expectation constraints. (This principle is applied in some specific machine learning tasks – such as, Inverse Reinforcement Learning, etc.)
3. Regression Family
In machine learning, different statistical model is used to address each problem respectively.
In this section, I’ll pick up several popular models used in regression, and show you how MLE is applied.
(This section will be the main part of this post.)
Note : All statistical models discussed in this post belongs to exponential family. (See above.)
In this chapter, I’ll separate topics into each models, but all the theory written in this post can be generalized as the theory of exponential family.
Later (in the chapter 6) I’ll briefly discuss how to solve more difficult formula which doesn’t belong to exponential family – such as, Gaussian Mixture Models (GMM), etc.
Logistic Regression
Binomial regression with logit link function is called logistic regression. (Later I’ll show you what “logit link function” means.)
Now let’s briefly see the logistic regression example.
Suppose, it has the probability 


In this assumption, it’s known that the probability of this occurrence is :

where

This probability space is called binomial distribution.
When 

When a lot of pairs 

Now let’s consider using an example. :
Suppose, we have fishes in the fish tank, and we survey the survival rate depending on the amount of given food and the amount of given oxygen as follows.
Alive(y1) Dead(y2) Food(x1) Oxygen(x2)39 11 300 200030 20 150 120012 38 100 1000...Now we denote the probability of survival in i-th case as 

The joint probability is then written as follows. (Suppose, all pairs 

Our goal is to find the optimal parameters 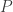
The solution is then analytically obtained by the gradient descent or Newton-Raphson method with partial derivatives. (In this post, I’ll skip the detailed procedure for these methods.)
In this assumption, there exists a trick. Is that really
In logistic regression, the following formula is often used for the linear predictor, instead of
This formula is called sigmoid function.

In the later section (in the chapter 4), I’ll give you the reason why this formula is used. (So, please skip the detailed reason here.)
As a result, the estimation function of the logistic regression will then be re-written as follows :

Note : It’s known that it’s possible to analytically find the optimal
when it’s exponential family.
Now let’s see the program code with R script.
First I have generated sample data (1000 rows) with 


rbinom() function).
library(e1071) # for sigmoid func###### create sample data with rbinom###### y1 : number of alive# y2 : number of dead# x1 : food# x2 : oxygen#####n_sample <- 1000total <- 50b0 <- -15b1 <- 4b2 <- 2x1 <- runif( n = n_sample, min = 0, max = 5)x2 <- runif( n = n_sample, min = 0, max = 5)probs <- sigmoid(b0 + b1 * x1 + b2 * x2)y1 <- rbinom( n = n_sample, size = total, prob = probs)y2 <- total - y1sampledat <- data.frame( x1 = x1, x2 = x2, y1 = y1, y2 = y2)To estimate the optimal parameters, call glm() function in R script as follows.
With binomial() setting, this function solves regression problem by binomial distribution.
By “link=logit” setting, a logistic sigmoid function (see above) is used in a linear predictor.
###### Estimate#####fit <- glm( cbind(y1, y2) ~ x1 + x2, data = sampledat, family = binomial(link = "logit"))summary(fit)Note : The default link function of binomial distribution is “logit” in R. You don’t then need to specify
link = "logit"explicitly. (Here I have explicitly specified for your understanding.)
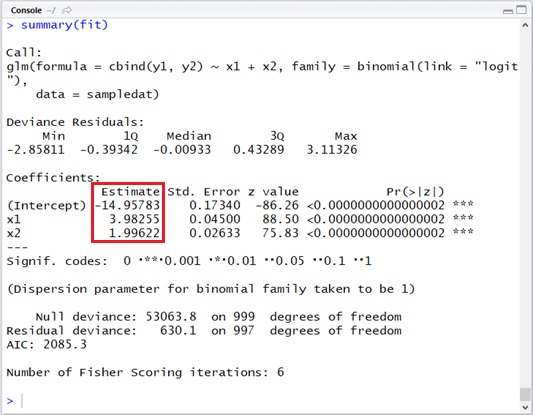
By running this code, we can get the optimal result : 


As you saw above, this result is near the actual values.
Let’s see another example.
The following dataset is similar to the previous one (sampledat), but each of rows has 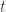
sampledatA
Survival(t) Food(x1) Oxygen(x2)1 300 20000 100 10001 300 20000 100 10000 300 20001 300 20001 100 1000...Now I denote 
Same as above, we can get the optimal parameters by solving the maximum likelihood of this joint possibility.

In order to get this estimated results (
## with "Survival" column t (0 or 1)fit2 <- glm( t ~ x1 + x2, data = sampledatA, family = binomial(link = "logit"))summary(fit2)As you can see, this dataset (above sampledatA) can also be written by the following format (sampledatB), which is the same format as previous one.
Of course, this then leads to the same solution,
sampledatB
Alive(y1) Dead(y2) Food(x1) Oxygen(x2)3 1 300 20001 2 100 1000...Poisson Regression
Let’s see another example in regression family.
Suppose, some event occurs 
It’s known that the probability 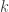
This stochastic distribution is called Poisson distribution.

Now let’s consider using a following example. :
Here we plant some seeds in our garden, and we survey how many seeds germinate depending on the amount of water and fertilizer.
In this model, we consider that

In practical use-case in Poisson regression, the following function is often used as 
In the later section, I’ll also give you the reason why this link function is used. (Please ignore here for this formula of link function.)

Suppose, a lot of data of
Germinating(k) Water(x1) Fertilizer(x2)11 300 20008 150 12005 100 1000...We can then define the joint probability by multiplication as follows.
Our goal is to find the parameters

Note : In most cases, the estimation is performed by minimizing
, instead of maximizing
See about loss function in above note.
Let’s see the following simple example with R to solve this regression problem.
Using rpois() function, here we also generate the simulated data (1000 rows) with random noise (errors) using 


glm() function.
###### create sample data with rpois###### y : germinating# x1 : water# x2 : fertilizer#####n_sample <- 1000b0 <- 0.2b1 <- 0.5b2 <- 0.4x1 <- runif( n = n_sample, min = 0, max = 5)x2 <- runif( n = n_sample, min = 0, max = 5)lamdas <- exp(b0 + b1 * x1 + b2 * x2)y <- rpois( n = n_sample, lambda = lamdas)sampledat <- data.frame( x1 = x1, x2 = x2, y = y)###### Estimate#####fit <- glm( y ~ x1 + x2, data = sampledat, family = poisson(link = "log"))summary(fit)Note : The default link function of Poisson distribution is “log” and then you do not need to specify
link = "log"explicitly in R.
As you can see in the following output, the estimated results are 


As you can find, the result is well estimated.
Linear Regression (Gaussian Regression)
Linear regression (Gaussian regression) will be mostly primitive and widely used regression model in machine learning, but you should understand how it’s related to the familiar Gaussian distribution (normal distribution).
First, we consider this regression very straightforward to ease the problems.
Suppose, the formula with primitive linear expression is given. Now we want to find the optimal parameters 

As you saw above in previous examples, we have applied maximum likelihood estimation (MLE), which will maximize the joint possibility in stochastic distribution models.
But here, we don’t use MLE and dare to use the ordinary least squares (OLS) for estimation, which minimize the sum of distance squares (or MSE) between observed values and predicted values.
Now let’s see the brief example.
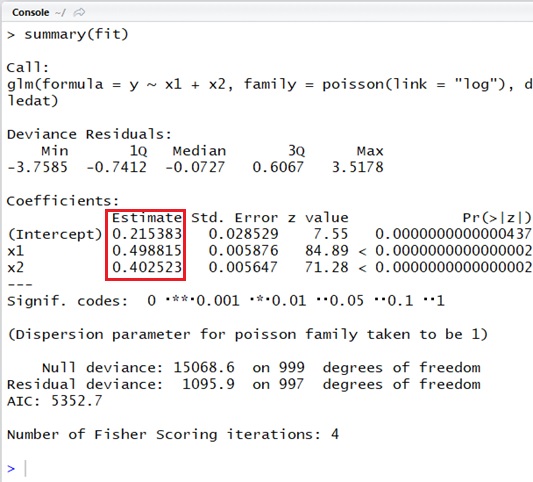
For simplicity, we assume that the only 
In ordinary least squares (OLS) method, first we calculate each distance between the observed value 
The value of distance might be positive or negative. We then sum up the square of each distance as follows.
Our goal is to find the optimal parameters 




Why is it called “Gaussian” ?
Now let’s consider the normal distribution (Gaussian distribution)
We then consider the maximum likelihood estimation (MLE) for this Gaussian distribution.
Suppose 


If

Now we apply the logarithm for this equation (i.e, log-likelihood) and it’s then written by :

As you can easily see, we can get the maximum likelihood when we minimize 


Therefore, maximum likelihood estimation (MLE) under Gaussian distribution (i.e, linear regression) is equivalent to applying ordinary least squares (OLS) method (minimizing MSE).

Note : When the standard deviation (or variance) is unknown and the number of observations is small, we sometimes consider the marginal distribution of Gaussian distribution on the precision (which is the inverse of a variance), instead of using Gaussian distribution. This distribution is called Student’s t-distribution.
It’s known that Student’s t-distribution is more robust to outliers than Gaussian distribution. (Gaussian distribution is a special case of Student’s t-distribution.)
It’s known that various phenomenon in nature (including random trials) will follow Gaussian distribution, because the continuous (not discrete) distribution to maximize an entropy is Gaussian distribution. (See above note for entropy in information theory.)
Therefore linear regression is then applied in a lot of cases in practices.
Suppose, the average amount of human’s daily salt intake might also follow Gaussian distribution
Also, suppose, the mean
In this case, you can get the regression result by MLE under Gaussian distribution (or OLS) with linear predictor 
Let’s see the following simple example with R script.
As you can see below, here I generate the data (1000 rows) with random noise (errors) using 

rnorm() function. (The data will then be generated on normal distribution.)
And I then estimate parameters with glm() function.
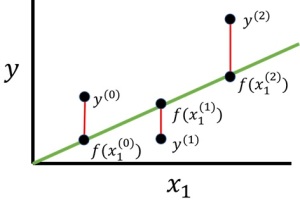
###### create sample data###### y : salt intake (g / 10 days)# x1 : weight (pond)#####n_sample <- 1000b0 <- 44b1 <- 0.14x1 <- runif( n = n_sample, min = 45, max = 180)epsilon <- rnorm( n = n_sample, mean = 0, sd = 1.57) # noise (variance)y <- b0 + b1 * x1 + epsilonsampledat <- data.frame( x1 = x1, y = y)###### Estimate#####fit <- glm( y ~ x1, data = sampledat, family = gaussian(link = "identity"))summary(fit)Note :
link="identity"means the link function with. (That is, the linear predictor is not modified to other formula.)
The default link function of Gaussian distribution is “identity” in R. Then you do not need to specifylink = "identity"explicitly.
As you can see in the output, the estimated results are 

Gamma Regression
Finally I’ll introduce Gamma regression.
Suppose, some event occurs 
It’s known that the probability density function 


where 
Note : Same as Gaussian distribution, it’s a probability density function, not a probability function.
Same as MLE in linear regression, you should use integral or get the probability with some fixed small range
Here I don’t go details about this function’s form, but Gamma function is an extended form of factorial operation 
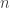
Note : I show you examples of Gamma distribution for several
This regression is often used for the analytics, such as, waiting time, time between failure, accident rate, so on and so forth.
There exist two parameters
For example, let’s consider the time of the failure (breakdown) for some equipment using Gamma regression.
Suppose, this occurrence depends on the count of initial bugs 
When the count of initial bugs increases, the errors in production would also increase. That is, when 

In the practical use-case, the following inverse link function is then often used for Gamma regression. (I’ll describe the details about this link function later.)
Here 

Note : Here I don’t explain about details, but
of Gamma distribution is
.)
Let’s see the following simple example with R script.
As you can see below, here I generate the simulated data with random noise (errors) using 


rgamma() function.
And I then estimate parameters with glm() function.
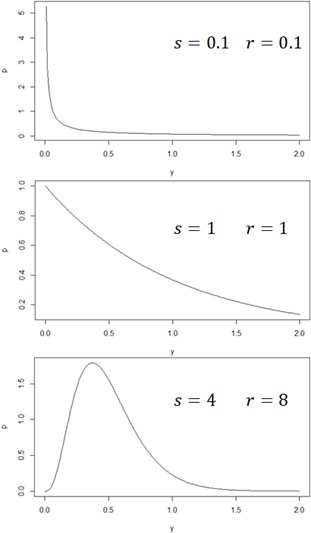
###### create sample data with rgamma###### y : time to failure# x1 : number of initial bugs# x2 : number of customer claims#####n_sample <- 1000shape <- 10b0 <- 0.5b1 <- 0.02b2 <- 0.01x1 <- runif( n = n_sample, min = 1, max = 5)x2 <- runif( n = n_sample, min = 11, max = 15)rate <- (b0 + b1 * x1 + b2 * x2) * shapey <- rgamma( n = n_sample, shape = shape, rate = rate)sampledat <- data.frame( x1 = x1, x2 = x2, y = y)###### Estimate#####fit <- glm( y ~ x1 + x2, data = sampledat, family = Gamma(link = "inverse"))summary(fit)As you can see in the following output, the estimated results are 


If you need the value of shape (gamma.shape() in MASS package. (You can then get the original model of Gamma distribution.)
library(MASS)...# you can get shape as follows.test <- gamma.shape(fit, verbose = TRUE)4. Link Functions
In the previous examples, I have used several link functions without making it clear, but now it’s time to explain about link functions.
Designing link functions is also important part in regression modeling.
Note : The inverse of link function is called activation function. In this section, I’ll discuss using a formula of activation functions .
Log Link Function
Remind the previous Poisson regression example (example of plant’s germination).
I assume that

Suppose, the seeds have germinated 1.5 times a lot by some increase of water. And also the seeds have germinated 1.2 times a lot by some increase of fertilizer.
If you increase the same amount of both water and fertilizer, the seeds would germinate 1.5 + 1.2 = 2.7 times a lot ?
Of course, Not. We will expect that it will germinate 1.5 * 1.2 = 1.8 times a lot.
Therefore formula (1) doesn’t represent our expected model.
Now we correct this formula as follows.
This is called a log link function. The reason of this name is that the linear predictor 
When we replace with 



When 


Using formula (1), it can also be a negative number when
For these reasons, log link function is often used in the regression under Poisson distribution.
Of course, the log link function would not always be the answer in Poisson regression. The important thing is to understand this background idea and use the appropriate link function along with your problems.
Logit Link Function
The logit link function is used for representing the value between 0 and 1. Therefore it’s then often used in logistic regression. (This idea is also used in 2-class classification task in today’s neural networks.)
Let’s go dive into logit link function.
Remind the previous logistic regression example (the fish survival example).
Now we consider the following logical model. :
- Each input of
and
respectively.
For instance, when the oxygen is so critical rather than the food for survival,
It then gets the total weight by.
- Compare this total weight with some fixed threshold
.
If it’s exceed. Otherwise, the result
. (See the following picture.)
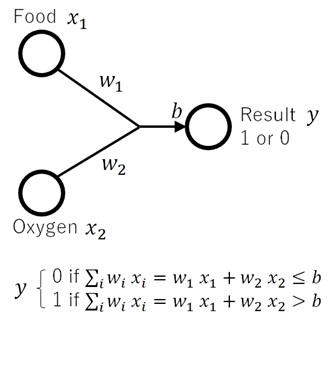
This model represents the aspect of the actual decision mechanism. But one important drawback is that it is not continuous and it’s a discrete function.
The following picture shows the plotting when we suppose 
Because of this, some mathematical operations (such as, differentiation) will be difficult to apply.
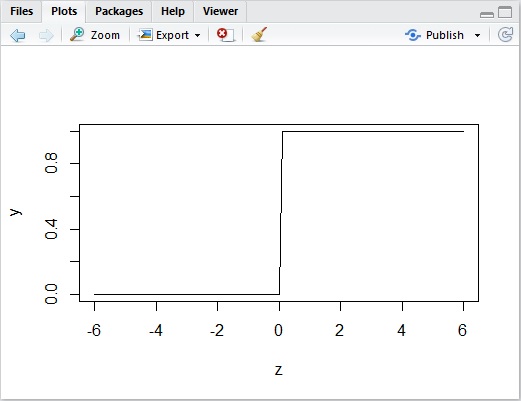
Therefore we introduce the following activation function called a logistic sigmoid function.



As you can see below, the curve of this sigmoid is very similar to the previous one, but it’s continuous (not discrete).
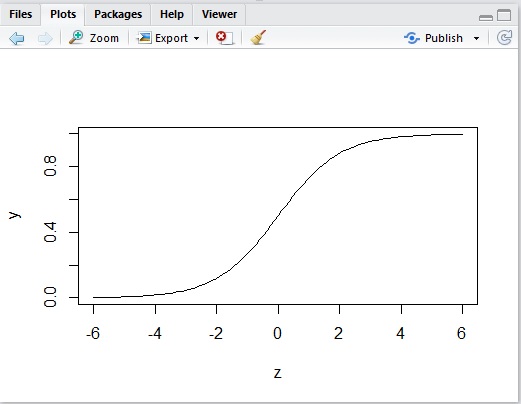
Note : For simplicity, here I discuss things on the assumption that the formula of logistic sigmoid function is given. However, this formula can be derived statistically.
Please remind that the formula of Gaussian distribution (normal distribution) has exponential part, and you will then find the logistic sigmoid function is well-defined for the inputs with Gaussian distribution. Not only Gaussian distribution, but other well-known distributions in exponential family are all statistically related to logistic sigmoid function (when it’s in 2 classes) and softmax function (when it’s in multiple classes).
I also note that there is close similarity between logistic sigmoid function and the cumulative distribution of Gaussian distribution. The cumulative of Gaussian distribution is sometimes approximated by using a logistic sigmoid function.
Now we suppose 



The logit link function is the inverse of this logistic sigmoid function as follows. :

Note : As you can see, this
is representing the probability of dead. This ratio of
is then called odds.
In neural networks, this idea (sigmoid) is extended, such as :
- As you saw above,
sigmoid()is in the range (0, 1). Now you can considertanh()as the analog of sigmoid for the range (-1, 1).
Since, then
tanh()is equivalent tosigmoid()except for the range. - As you saw above, the input (which might positively exceed 1 and also negatively exceed -1) is interpreted into 2 classes (i.e, 0 or 1), by a logistic sigmoid function. For the multiple
), you can use softmax function instead, in which the possibility for class
is represented by
whereindicates the linear predictor’s output (sometimes, called “logits”) for class
.
Since, then you will find that it’s the extension of the logistic sigmoid function for multiple classes.

Note : In softmax function, the output
The logits will be any real number, butwill become positive number, and finally it’s normalized (into the range (0, 1)) by
.
The softmax function is often used for activation function in today’s neural networks.Note : In neural networks, it sometimes introduces the following parameter
, called temperature. When
, the distribution becomes peaked around the origin. On the other hand, when
, the distribution flattens out.
There’s a trade-off between coherence (low temperature) and diversity (high temperature).

Inverse Link Function

Remind the previous Gamma regression example (example of errors and failure).
In this example, predicted parameter
Because 

where 



As I have explained in Gamma regression,
In case when the linear predictor is proportional to the scale (i.e, inversely proportional to the rate), you should specify identity link function in Gamma regression as follows, instead of specifying inverse link function.
fit <- glm( y ~ x1 + x2, data = sampledat, family = Gamma(link = "identity"))Note (About Offset) :
When you want to specify some input variable without predicted coefficient, such as, you can use offset.
For instance, now we introduce new input variable “observation count” (
) in the previous example of Poisson regression (example of plant’s germination).
Then the following linear predictor will be used.
In such a case, you can use offset as follows.
fit <- glm( y ~ x1 + x2, data = sampledat, family = poisson(link = "log"), offset = log(x3))You might think that you could just divide the result

5. Evaluation Metrics
After the model is trained, you should evaluate how well it fits to the actual data.
Here I’ll only show you the popular evaluation metrics for regression, with its notations.
By using these metrics, you can quantitatively measure how well the model fits.
The good model will fit not only to given data (the data used in training), but also to unseen data. For this reason, the unseen data (which is not used in training) is usually used for the evaluation.
Mean Squared Error (MSE)

where :
is predicted value.
The difference between true value 
Compared to the following MAE (Mean Absolute Error), this value is differentiable and this metric is then easily optimized while training the model.
Mean Absolute Error (MAE)

where :
Instead of squared value for difference in MSE, this metric (MAE) uses the absolute value of difference.
As I have mentioned in above note (see note for quadratic loss function and absolute loss function), a few large outliers will influence the squared value of difference, while the absolute value of difference cannot be affected so much.
Root Mean Squared Error (RMSE)

where :
By applying the square root for MSE, this metric is expressed at the same scale as the target variable.
Other than scale, RMSE has the same properties as MSE.
R-squared (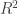 )
)

where :
(i.e, the mean of true data).
If the model is fitted by OLS (or MLE under Gaussian distribution), the range of R-squared will always become between 0.0 to 1.0. When all predicted values fit to the observed (actual) values, this metric will be close to 1.0. Otherwise, it will close to 0.0.
However, R-squared metric might sometimes be negative, when the generated model doesn’t follow the trend of the data in non-linear models.
In general, when the variance of data is larger, the absolute difference between observed values and predicted values will also become larger. So, by dividing by the variance (i.e, 
Unlike MSE, MAE, and RMSE, this value is scale-independent.
For instance, even when the unit of data is changed from inches to foots, the result of this metric won’t be changed. (On contrary, above other metrics are scale-dependent.)
6. Further Learning … : Other Methods for Regression
Now you’ve learned the major algorithms based on MLE.
Finally I’ll briefly show you shortcomings of MLE and more advanced techniques to solve these problems for your further learning.
Bayesian statistics
The “likelihood” approach (discussed in this post) will not always be the best for some problems.
To show you a brief example, let me assume that it happened all results are “head” in coin flipping trials (Bernoulli trials).
In this case, however, you would have a wrong model which tells 100% head by using above frequentist algorithms (MLE method) discussed in this post, even when it’s only several trials.
As you can see in this simple use-case, MLE often leads to the over-fitting (i.e, loss of generalization) problem.
Another is a singularity problem in the likelihood estimation (MLE).
For instance, let me assume Gaussian mixture model (GMM), which is the distribution by the sum of multiple Gaussian distributions (with balanced ratios). When the observed data is exact same as a mean of some Gaussian component in GMM, the joint probability in MLE can go to infinity when 
This example also shows that MLE tends to lead to over-fitting.
In Gaussian distribution, it’s known that the variance obtained by MLE has more large bias (i.e, the smaller variance) rather than the actual one, especially when the number of trials is small. (See below note.)
By introducing Bayesian inference, you can obtain information about how the parameters in model are distributed, not only obtaining the best-fitted parameters. By considering parameter’s distribution 


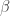
With this idea, the model by Bayesian statistics can avoid above problems.
Here I don’t go so far, but all models discussed in this post can also be treated as Bayesian manner (such as, logistic regression –> Bayesian logistic regression, etc).
Bayesian statistics is also applied to a variety of methods in today’s machine learning, such as, automatic relevance determination (ARD), variational methods, so on and so forth.
Note : Let me assume Gaussian regression (i.e, linear regression), in which the number of observation values is
It’s known that the expectation of mean. The expectation of variance
By introducing Bayesian statistics, you can get the distribution of estimated parameters
as posterior distribution by using the prior distribution of these parameters. By feeding more inputs (
), the posterior distribution will lead to actual distribution in parameters.
Bayesian modeling gives a lot of other beneficial aspects.
For instance, when you apply Bayesian inference in Gaussian regression, it’s known that it gives the same effect of applying L2 regularization, which prevents from over-estimation or over-fitting (loss of generalization).
Another superior characteristics in Bayesian modeling is sequential nature. Because posterior distribution is obtained by the prior distribution, it’s not needed to load all inputs in memory and can be trained sequentially by the subsequent inputs. (You can also take alternative techniques – such as, sequential gradient descent – for sequential learning in MLE.)In Bayesian statistics, the prior distribution at the starting point is experimentally decided among conjugate priors.
By introducing the technique of evidence approximation, you can also find the appropriate parameters in conjugate priors.For the further reading, see “Pattern Recognition and Machine Learning” (Christopher M. Bishop, Microsoft), in which a lot of methods of Bayesian perspective are discussed.
Iterative methods
We might also encounter more complex models – such as, Gaussian mixture models (GMM), Hidden Markov Modeling (HMM), etc.
These models are difficult to be solved by analytical (or arithmetical) methods mentioned in this post.
For these advanced models, procedural iterative methods based on stochastic graphical modeling are often applied – such as, EM (expectation-maximization) algorithm or variational inference (variational Bayes).
In EM algorithms, parameters can be estimated by the iterative and algorithmic process, based on maximum-likelihood estimation (MLE).
In variational inference, it’s based on Bayesian approach and the distribution of parameters can then be approximated also by the iterative and algorithmic procedure.
Note : See here for Python examples of EM algorithm and variational inference in Gaussian mixture models (GMM).
Here I don’t go so far, but these methods can also be applied to regular regression problems – such as, variational Bayesian linear regression, variational Bayesian logistic regression, etc.
Non-parametric methods
When it’s hard to take a specific mathematical model (such as, Gaussian distribution, Poisson distribution, GMM, etc) or it’s unknown distribution, you can also apply non-parametric approach – such as, histogram density, locally weighted regression (LWR), or Parzen estimation (with kernel trick).
In above examples (MLE examples), I have assumed that all predictors are linearly provided by 
For instance, in Parzen estimation, firstly we map original space into high-dimensional space by 


As you can easily see, searching any appropriate functions over possible and unknown 
Parzen estimation enables them to operate in high-dimensional spaces without searching and identifying
Here I don’t go so far about kernel methods, but see “RBF Kernel” section in my post “Mathematical Introduction for SVM and Kernel Functions“.
Also in Gaussian process (GP) regression, it updates the posterior by new observations (which technique has been seen in Bayesian) to fit to all observed data, with the same manners.
But these methods are computationally intensive, because the computational complexity grows depending on the size of the training (observation) data.
When the mathematical model is unknown, you can also experimentally get the distribution by Monte Carlo sampling – such as, in Particle Filter method.
Neural networks
Deep neural networks are known for being any approximators (i.e., they can learn any functions) and a lot of today’s real tasks are experimented by using neural network learners.
This analogy can also be applied in regression problems.
Suppose, we have a multi-layer perceptron (MLP) network.
If all activation functions in layers are linear (or identity), the network will then become equivalent to regular GLM regression discussed in this post. (It will then be nonsense to use neural networks.)
In general, the complexity in neural networks is realized by adding non-linear activations in multiple (hidden) layers, and the linear activation function is then applied in the final unit to predict the output.
The neural networks have ability to approximate functions which are hard to build with existing statistical algorithms.
For instance, suppose, there exists multimodal time-independent frequency for some single input
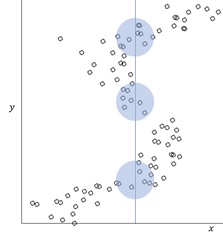
Furthermore, the computational complexity of non-linear neural networks doesn’t grow even when the size of training data becomes large, unlike previous non-parametric methods.
The complexity, however, grows depending on the size of a network.
Especially when the size of network is large and deep, you should take care that they are often difficult to interpret (explain) the generated model and also hard to get the generalized results in the worse cases. (See over-fitting .)
In the simple task, hence, it’s better to apply a simple method. (The bigger, not always better.)
In the last part of this post, I have discussed the outlines of several advanced methods for regression.
But the basic ideas you have learned in this post will also help you understand these advanced ideas for your further learning.
Categories: Uncategorized

Thanks for sharing
LikeLike