
Support vector machine (SVM) in machine learning is so useful in the real classification (or anomaly detection) problems, since this learner covers many of scenarios and it doesn’t require the complicated tuning, which is often needed in neural network modeling.
However, it’s necessary to know about the idea of this learner in order to tune parameters, minimize loss, so on and so forth, in practical use.
In this post, I describe how SVM (support vector machine) works and make you understand strengths and weaknesses in the practical use.
Of course, the idea behind SVM is based on mathematics (statistics), however, for the purpose of building your intuitions, I’ll try to explain with a lot of examples and visualizations as possible.
This post will also help you understand kernel methods, which is used behind SVM.
Maximum Margin Classification
To begin discussion, first I show you the idea of maximum margin classification.
In this post, I’ll start with a simple linear classification example (trivial model with a simple linear function), and later we’ll discuss more difficult and practical problems in margin maximization, which eventually leads to the method of SVM.
As you can see later, there’re several kinds of SVM learners (C-SVM, ν-SVM, One-class SVM, …), but all are commonly based on the idea of margin maximization, and you’ll find why the name of this learner implies “support vector”.
First, let’s see the following 2-class linear classification example, which has inputs of 2-dimensional vectors 
Assume that we have 


Note : I’m sorry, but the syntax for both
and
might confuse you. In this post, I use
for a scalar value, and use
for a vector value. (Then
here.)
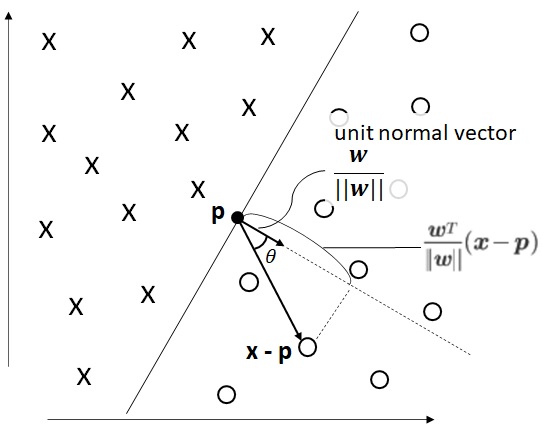
As you can easily see in above picture, this data can be linearly classified. Then, when we denote 
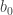



Dividing these equations by 





Now we pick up some position vector 

Using this vector

What’s 
The value 


Note : That is,
decides the direction of boundary (decision hyperplane).
Eventually, every 

As you can see below, this margin will differ when the decision boundary has changed.
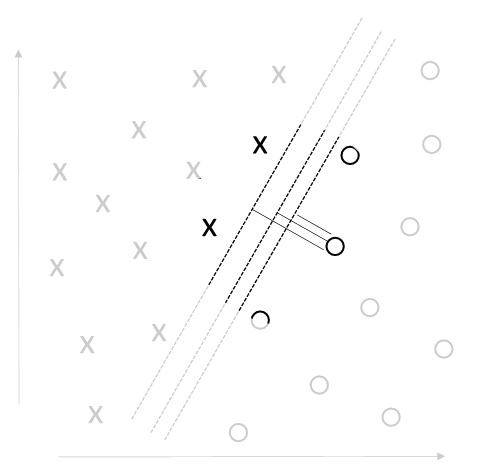
Now we assume that all input’s vectors are not on the boundary. (If there exists a vector on exact boundary, please change the boundary away from that.)
As you saw above, 


Then the equations (1) and (2) will be written as a following single equation.

We assume 
Then the above equation will be written as follows.

The decision boundary 

Then the above equation will also written as follows without losing generality. In the following equation, I replaced 


Now let’s consider which one is the most optimal decision boundary.
First, as you can see below (see the following picture), the decision boundary will become better, when the minimum margin 
Then you should find 
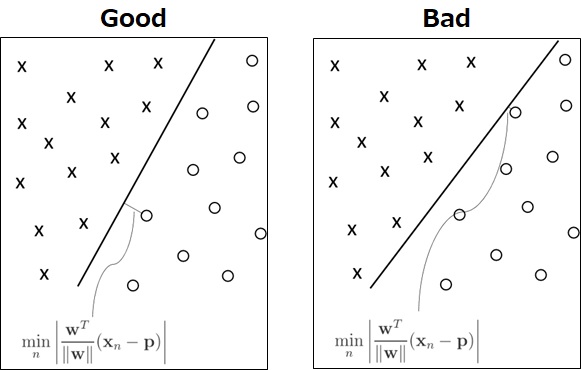
Second, when the decision boundary
Let’s see the following picture. If you change
Thus, in order to maximize margin 
Note :
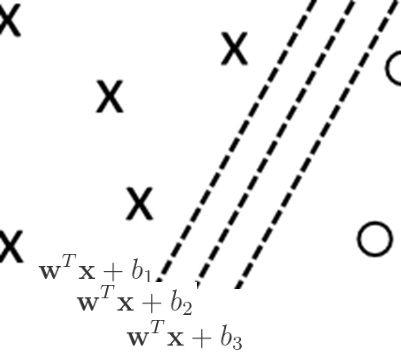
Here I note that there exist 




Now let’s consider how the margin is give by
As you saw above, the margin of each 






Then, in order to maximize the class margin, you should find parameters 

This problem is the conditional min/max problem with inequality constraints, and we then apply the following KKT (Karush–Kuhn–Tucker) conditions with Lagrange multipliers 
KKT condition
Find parameters 






Note : Especillay, the condition 5 is important in KKT.
For simplicity, let me assume a single Lagrange multiplier (i.e,
).
When a Lagrange multiplieris equal to 0 (i.e,
in condition 5), the condition 1 means that the optimal
, and you will then find that data point
.
This intuitively implies that the limit is within the range of inequality constraints, such like the left side of the following picture. (In this picture,
When a Lagrange multiplier
), the condition 5 says that the optimal
In this case, the data point

Here I don’t go so far, but this problem yields to the following equivalent problems with only Lagrange multipliers
This equivalent representation is called dual representation in mathematics.
Dual representation
Find 

Subject to :
for all


Note : The objective function
When 

As you saw earlier, the vector (input data) which has the minimum margin is especially important for this problem. Then this vector is called a support vector in SVM.
For instance, all of the following 5 vectors are support vectors.
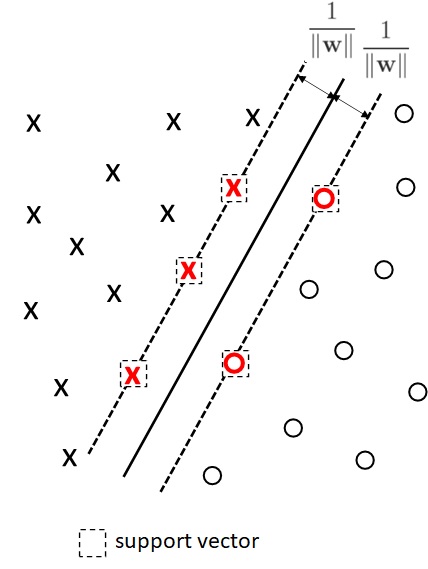
As you saw above, this problem is to get the optimal parameters by minimizing
Introducing Kernel Methods
In above example, we saw the idea of support vector machines (SVM) using a trivial linear classification. But, the real problem is not so simple.
From here, we enter into more practical topics step by step.
For instance, let’s see the following input vectors.
As you can easily see, this cannot be classified by any of linear decision boundary.
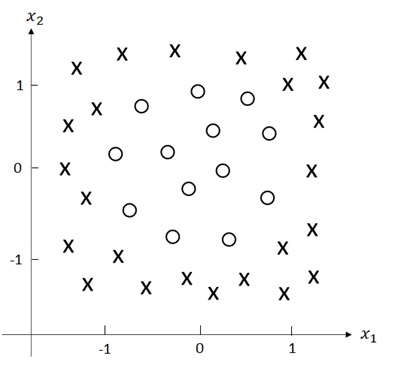
Now let me introduce kernel tricks in this section.
In order to make it classified by linear decision boundary, we assume that the above 2-dimensional vectors are mapped into more high dimensional space.
For example, let us assume that above 2-dimensional vectors are mapped into 3-dimensional vectors by the following mapping definition.

With this mapping, the data is easily classified by the 3-dimensional hyperplane, which is the grey-colored plane 
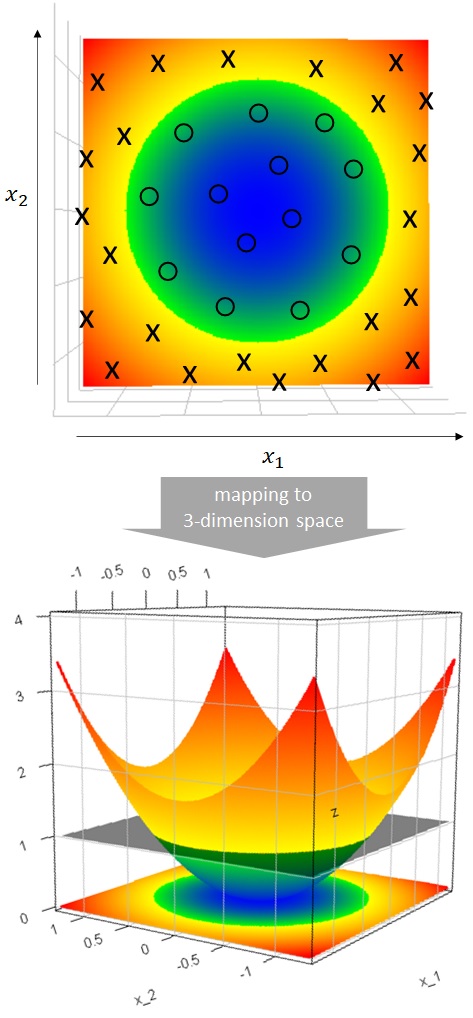
Note : As you see in above picture, the mapped coordinates
are not dense. (It’s a 2-dimensional manifold embedded in 3-dimensional space.) Thus the learner with this method (with which, the inputs are mapped into high dimensional space) is sometimes called “sparse kernel machine”.

When
Dual representation
Find

Subject to :
When Lagrange multipliers, 

Now we denote 

Using kernel functions, we can write above (7) as follows. It’s simply given by a linear combination of the target values from the training set.

As you can easily see, above problem is all written (described) by unknown kernel 

Here I don’t describe proofs, but it’s known that many other loss functions or predictive functions (also, dual representations) in popular machine learning algorithms can also be written with kernel functions. (You can then use kernel methods in various machine learning problems.) For instance, when we apply regularized least square for regression problems with basis function : 


where 

Now
For instance, 





where

It’s known that sum, product, and composition of kernel functions are also kernel functions.
However, in most cases, the way without having explicitly to construct the original basis function 
Note : In kernel methods, it’s often used a matrix called Gram matrix, which has the value
on
element, where
Gram matrix is symmetric and should be positive semidefinite, if and only if
How should we obtain (or approximate) the appropriate kernel function in support vector machines ?
I’ll give you one of solutions for this question in the next section.
RBF Kernel – Why it’s widely used ?
In this section, we see RBF (Radial Basis Function) kernel, which has flexible representation and is mostly used in practical kernel methods.
RBF kernel 
Especially, the following form of kernel is called Gaussian kernel.

Note : It’s known that
is a valid kernel function, if
Gaussian kernel has infinite dimensionality.
In this section, I’ll show you how it fits to the real data and make you understand why this kernel (Parzen estimation) is so popular.
For simplicity, we discuss using previous linear regression at first
Now, to make things simple, let us assume the following binary classification of 2 dimension’s vector
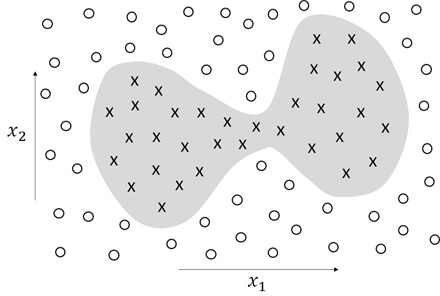
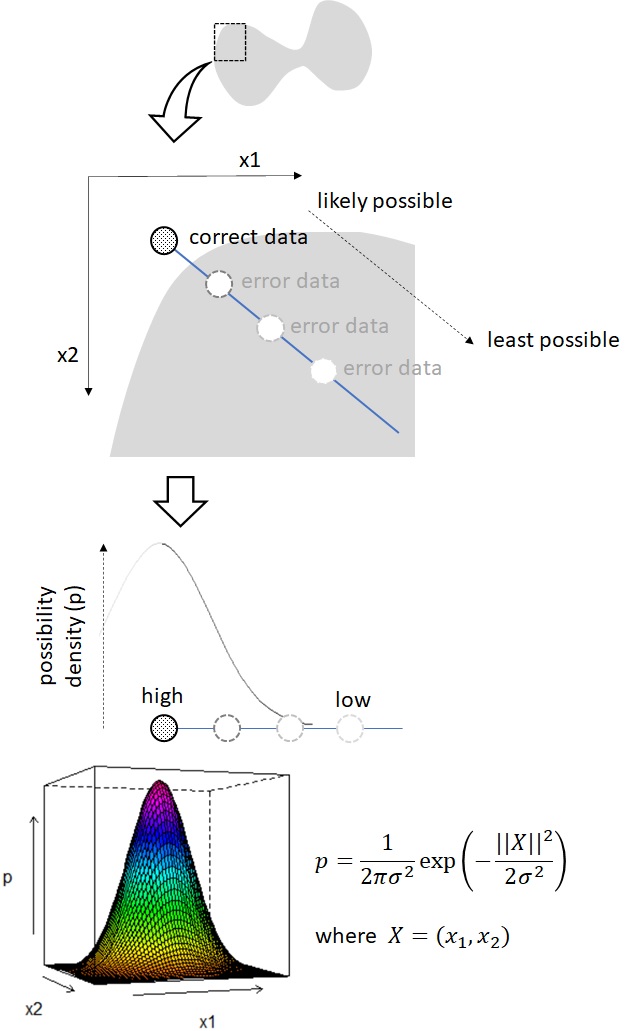
As you can easily imagine, you will see the error values with large possibility when it’s near the boundary, and with less possibility when it’s far from the boundary. As you can see below, the possibility of errors will follow the 2-dimensional normal distribution (Gaussian distribution) depending on the distance (Euclidean norm) from boundary.
Note : For simplicity, here we’re assuming that two variables
and
are independent each other, then their covariance is equal to zero. And we also assume the standard deviation for
.
(i.e, the covariance matrix in Gaussian distribution is isotropic.)
On contrary, let us consider the error possibility of the following point.
As you see below, this will be affected by both upper side’s boundary and lower side’s boundary, and it will become the sum of both possibilities.
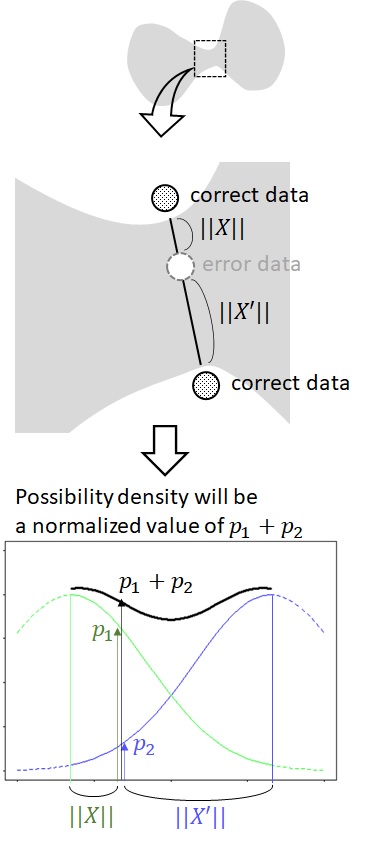
Note : If you simply add these possibilities (for upper-side and lower-side), the total possibilities will exceed 1. Thus, strictly speaking, you should normalize the sum of these possibilities.
Eventually the possibility of errors will be described as probability density distribution by the combination (sum and normalization) of normal distributions in each observed points.
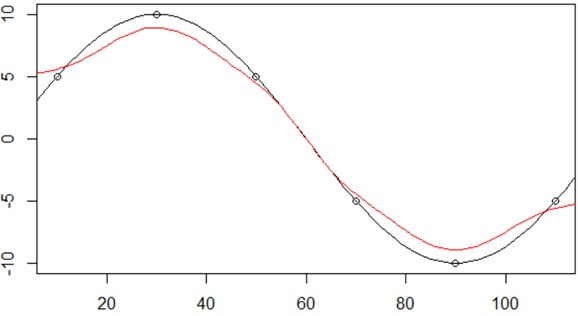
In order to see this in the brief example, let us assume the following 1-dimensional sine curve 
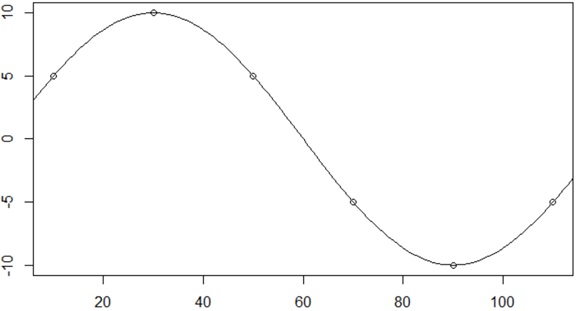
Then, by applying the following steps, we can estimate the original sine curve with these 6 points.
- Assume normal distributions (Gaussian distributions) for each 6 observed points.

- Get the weighted ratio for each distributions.
For instance, we assumeon
in above picture. Then the weighted value for each elements on
,
,
,
.
The following picture shows the weighted plots of each distributions.
- Multiply by each observed values.
For instance, if t-value of the first observed point is 5 (see above picture of sine curve), then theeffect of this first value (black-colored line) on
will be equal to
. (See below picture.)

- Finally, sum all these values (i.e, these effects) for 6 elements on each points of x-axis.

Please remind that the predictive function by linear regression with basis function can be written as the linear combination between target values (t) and kernel functions. (See previous section.)
As a result, you can easily estimate original curve by Gaussian kernel using the given observed data as follows.
Gaussian kernel has rich representation and can fit to a various kind of formula.
Note : Here I showed a brief example using a simple 1-dimension sine curve, but see chapter 6.3.1 in “Pattern Recognition and Machine Learning” (Christopher M. Bishop, Microsoft) for the general steps of Nadaraya-Watson regression (kernel smoother).
When
The value of standard deviation (

The value of standard deviation (
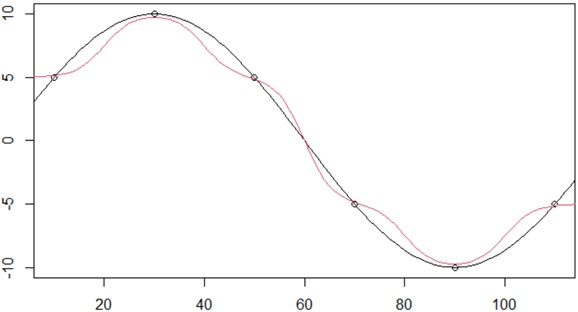
Note : Kernel density estimation (KDE) is the application for estimating the empirical probability density function (PDF) by applying this kind of Gaussian kernel smoother.
When
See “Mathematical Introduction to Regression” for the estimation application of parametric approach.
Now let’s go back to the equation (6) and (7).
In these equations, the formula of 
As you saw above, when
The kernel methods is very powerful, since it can be applied for various unknown stochastic distributions. But you should remember that the computational complexity will increase linearly by increasing the size of training data.
Note : In general, a regression function which forms a linear combination of kernel by the training set and target values,
, is called a linear smoother.
Here we got this form by intuitive thinking, but you can obtain the equivalent regression result by Bayesian inference (algebraic calculation) for a linear basis function.
Overlapping Class Distributions
Until now, we assumed that all data is exactly separated by support vector machines (i.e, hard-margin SVM). However, there’ll also be observed errors (noise) in practical SVM.
Here I show you soft-margin SVMs (such as, C-SVM and ν-SVM) which evaluate these losses.
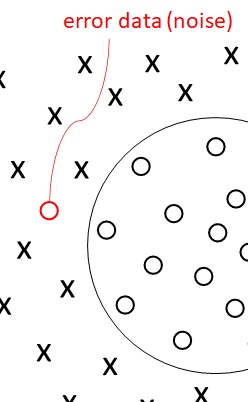
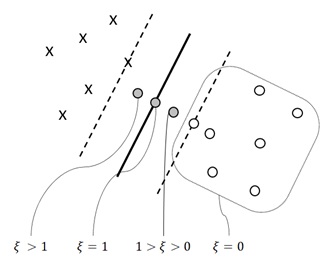
First of all, I introduce new variable 


, when it exceeds decision boundary.
, when it’s on decision boundary.
, when it’s between decision boundary and margin.
, others (when it’s correctly outside of margin, including support vectors.)
In the previous problems (without considering losses), we found
Instead, in this problem, we find the parameters 

Note : The above loss formula is also written by :
where
The part
is sometimes called hinge loss. (The name is because of the shape of the function
.)

Here the constant 
This is called C-SVM (C-support vector machine), and it’s also solved by dual representation with Lagrange multipliers. (I don’t describe this mathematical solution in this post.)
Let’s see another soft-margin SVM, called ν-SVM (ν-support vector machine).
In the previous C-SVM, if the number of inputs, 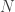
In ν-SVM, this bias is suppressed by using 
ν-SV classifier is defined as :
- Find
to minimize
- Subject to :
for any

With condition 

To prevent this unexpected learning, the term 
Same like 
Note : In this post, we’re discussing 2-class problems. However, even when only one class of data (i.e, only true data) is given, you can also obtain the optimal shpere by optimizing
This learner is useful, because it is usually difficult for you to collect sufficient error (outlier) data. This learner is called one-class SVM. (I note that there exists another type of one-class SVM, but I don’t go details so far in this post.)
See here for training and prediction by one-class SVM in Python.
Let’s consider how this
To see this, now I show you corresponding KKT condition for this ν-SVM as follows.
KKT condition

1.
2.
3.
4.
5.
6.
7.
8.







From condition 3 and 6, we get 
When we denote the number of support vectors as 

Then, from condition 4, we get :

It means that the ratio of support vectors is equal or larger than
On contrary, the vector which satisfies 

From condition 8, the bounded support vector has 

Then we get :

It means that the ratio of bounded support vectors is equal or smaller than
The following picture shows how
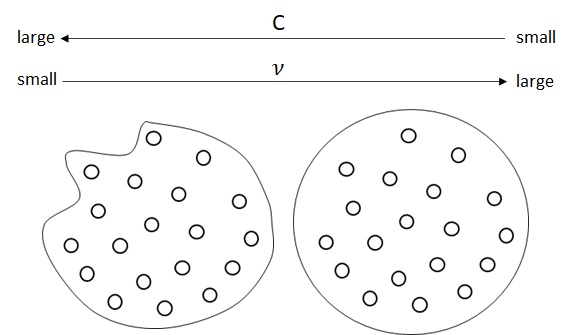
With high dimensional mappings, this parameter will affect the trained model, such as the following image.
In general, when
This parameter should be experimentally determined to fit the real problems, considering these trade-off.
Note : For details about overfitting, see my early post “Mathematical Understanding of Overfitting in Machine Learning“.
For training support vector machines in real computing, the analytical algorithm (such as, sequential minimal optimization) will be applied to fit in memory and scalability.
In this post, we have observed mathematics fundamentals behind SVMs and kernel tricks.
This idea of margin maximization gives you optimal solutions for high dimensional separation, and the idea is then also applied in a variety of other ML tasks – such as, inverse reinforcement learning (IRL), etc.
Reference :
“Pattern Recognition and Machine Learning” (Christopher M. Bishop, Microsoft), Chapter 6 and 7
Categories: Uncategorized
